【ZOL中关村在线原创技术解析】进入AI PC时代,ADVANCING AI峰会成为AMD这家半导体行业巨头与合作伙伴、开发者、用户以及产业链生态联盟沟通的桥梁。
就在刚刚,ADVANCING AI 2025成功举办。AMD在本次峰会期间公布了全新的CDNA 4 GPU架构,发布了AMD Instinct MI350系列GPU以及全新的ROCm 7,同时还针对AI时代面临的网络挑战,再次分享了AMD Pensando Pollara 400 NIC网卡的技术特性,至此,从CPU(EPYC)到GPU(Instinct),从前端网络到纵向/横向扩展网络,AMD能够为行业用户提供完整的AI系统解决方案。
除了全新的Instinct MI350系列GPU之外,AMD还预先披露了2026年即将发布的MI400系列GPU,它将把AI高性能计算GPU产品带入一个全新时代。
·CDNA 4架构与Instinct MI350系列GPU为AI计算而生
近年来,伴随着AI技术不断发展和突破,GPU成为最具AI生产力价值的核心硬件。全新的AMD CDNA 4架构,其核心设计理念就是聚焦在AI加速计算。因此,它集成了用于生成式人工智能和大语言模型的增强型矩阵引擎;支持混合型计算精度的全新数据格式;采用增强型无限互联架构与先进封装技术打造了Instinct MI350系列GPU,并且在能效方面实现进一步提升。
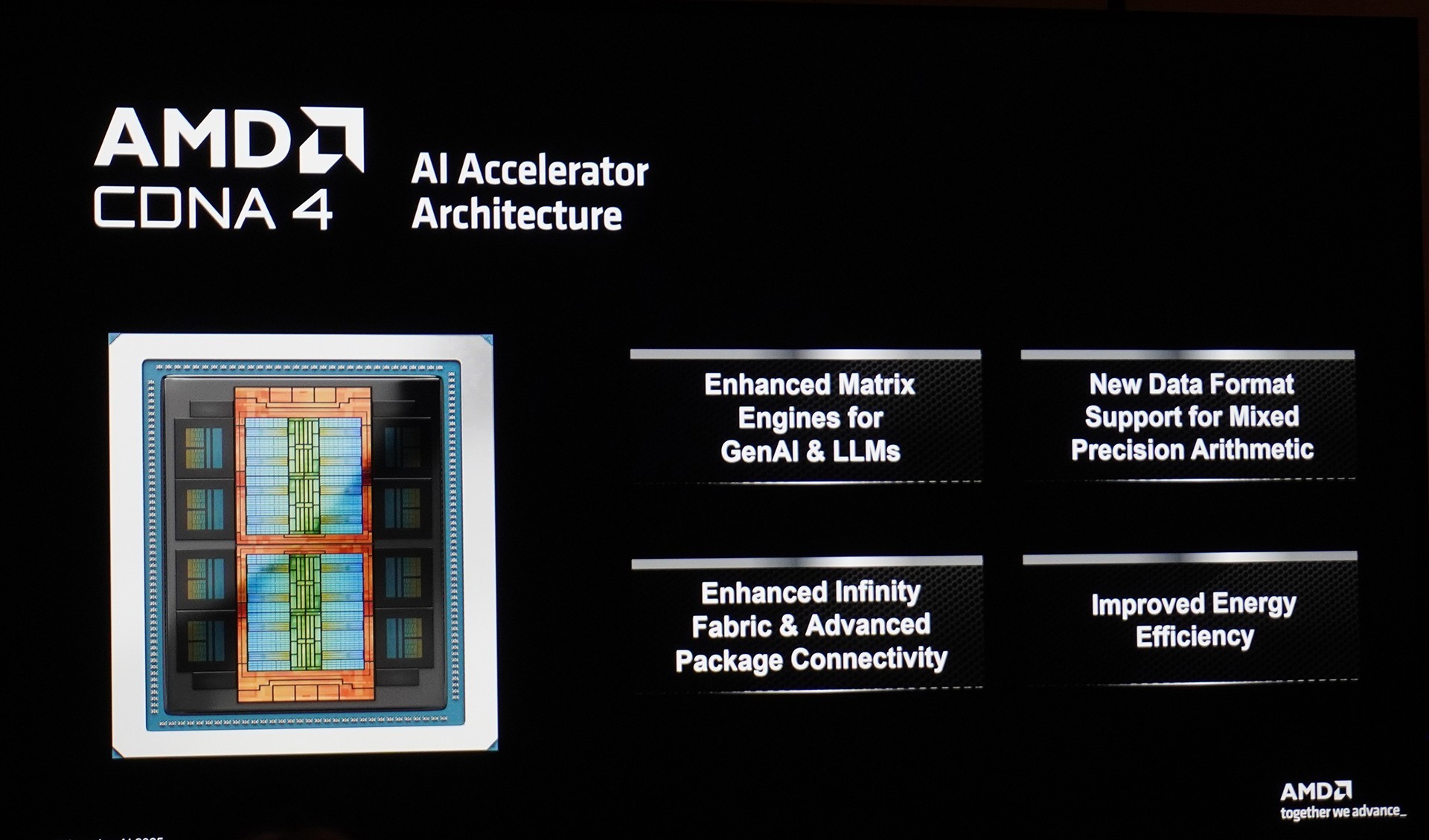
作为首个采用CNDA 4架构的AI加速卡,Instinct MI350系列GPU包含了峰值功耗1000W、面向风冷系统的Instinct MI350X以及峰值功耗1400W、性能更加强劲的面向液冷散热系统的Instinct MI355X。

其架构包含TSMC N3P工艺打造的XCD,并通过先进封装技术堆叠在TSMC N6工艺打造的IOD。并在HBM3E内存与IOD之间采用了2.5D封装技术进行整合。总体实现了在小尺寸芯片上采用台积电成熟的CoWoS-S封装技术。该技术通过在较大的硅中介层区域上提供高密度互连和深沟槽电容器,以容纳各种功能性顶部芯片,并在其上堆叠高带宽内存(HBM)立方体,进而实现高性能计算能力。

得益于增强型模块化小芯片封装,Instinct MI350系列GPU集成了8个32核AMD CDNA 4架构计算单元(XCD),它们通过3D混合键合架构堆叠在2个N6制成I/O裸片之上。
Instinct MI350系列GPU还支持128条HBM3E内存通道,采用双倍UTC支持高达288GB容量的12层堆叠的HBM3E内存,读取速率高达8TB/s,同时通过增加UTCL1/UTCL2大小选项、优化内存流水线等措施,满足高带宽需求的工作负载。

同时它拥有256MB AMD Infinity Cache,并采用了带宽速率高达1075GB/s的第四代Infinity Fabric。而两个XCD集群之间通过5.5 TB/s的Infinity Fabric Advanced Package实现高速互联。

Instinct MI350系列GPU有着非常灵活的分区,它最多支持8个空间分区,以最大化提升GPU利用率。NPS模式(NUMA Per Socket)从Instinct MI300X的NPS1和NPS4新增支持NPS1和NPS2。在SPX+NPS1模式下,Instinct MI350系列GPU能够支持520B,也就是5200亿参数的AI大模型;而在CPX+NPS2模式下,则可以最多支持8个Llama 3.1 700亿参数大模型实例,实现最大化的GPU利用率。

·双倍计算吞吐量升级 功耗不加倍
算力大幅提升的同时,Instinct MI350系列GPU的能效表现也更为出色,其设计目标就是改善AI工作流的性能体验。

为此,Instinct MI350系列GPU在功耗不加倍的情况下实现了双倍计算吞吐量提升。并且通过增强内存带宽和本地数据共享,进一步支持更高的计算吞吐量。同时它也实现了量化技术的创新。此外AMD还通过标准化将微缩数据类型引入社区,提供对FP8(缩放和非缩放)以及行业标准微缩FP6和FP4数据类型的完全访问权限,并且通过降低非核心功耗实现计算性能的提升。
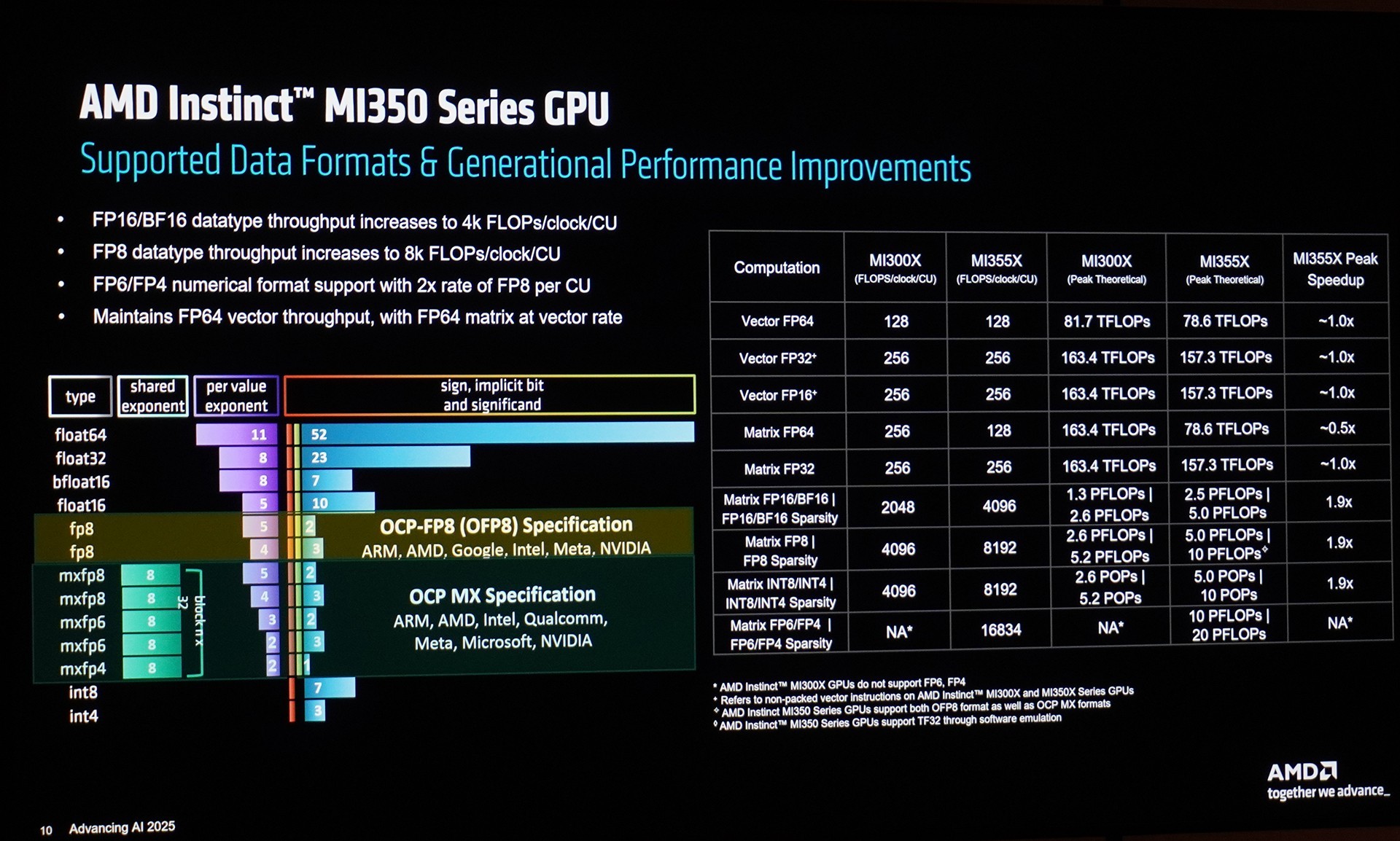
Instinct MI350系列GPU支持多种浮点精度数据格式,包括FP8、FP6、FP4、FP16、BF16以及FP64等。相比前代产品,其AI算力得到显著增强,FP16性能达到18.5 PFlops,FP8为37 PFlops,FP6/FP4高达74 PFlops。MI350系列GPU的模型参数处理能力从7140亿激增至4.2万亿,提升近6倍,能够有效满足大语言模型和混合专家模型的训练与推理需求。
此外,Instinct MI350系列GPU的增强型矩阵引擎每时钟周期、每个计算单元获得了2倍混合精度矩阵操作用于GEMM机制加速;以及2倍超越函数速率用于注意力机制加速。
接下来我们看看AMD官方给出的Instinct MI350X GPU在HBM内存读取带宽每瓦方面的表现,相比上一代MI300X GPU最高提升30%。每个计算单元的HBM峰值读取带宽速度提升超过50%。


此外,大家也可以参看下方表格,了解新一代MI355X GPU与上一代MI300X GPU在不同数据格式上的代际性能提升幅度。如FP16/BF16数据类型吞吐量提升至每个计算单元每时钟周期4k次浮点运算,FP8数据类型吞吐量提升至每个计算单元每时钟周期8k次浮点运算,FP6/FP4数值格式支持且每个计算单元的速率是FP8的2倍 ,并保持FP64向量吞吐量,FP64 矩阵运算速率与向量相同。
参考官方给出的Instinct MI355X与上一代MI300X GPU在Llama 3.1 405B大模型各类应用以及DeepSeek R1、Llama 3.3 70B、Llama 4 Maverick三款大模型的算力性能数据,MI355X GPU性能最低提升2.6倍,最高提升4.2倍,平均提升幅度在3倍以上。
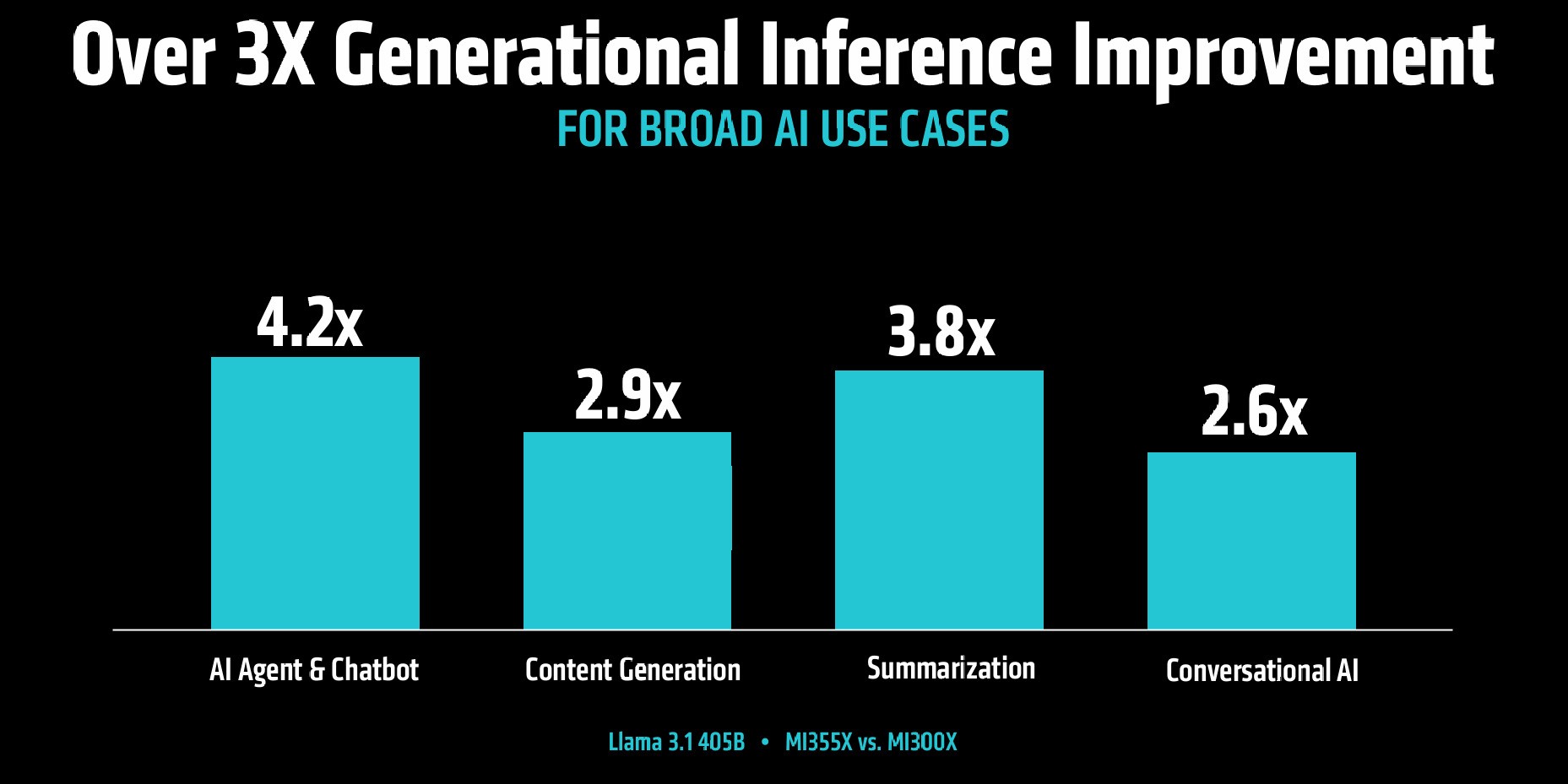
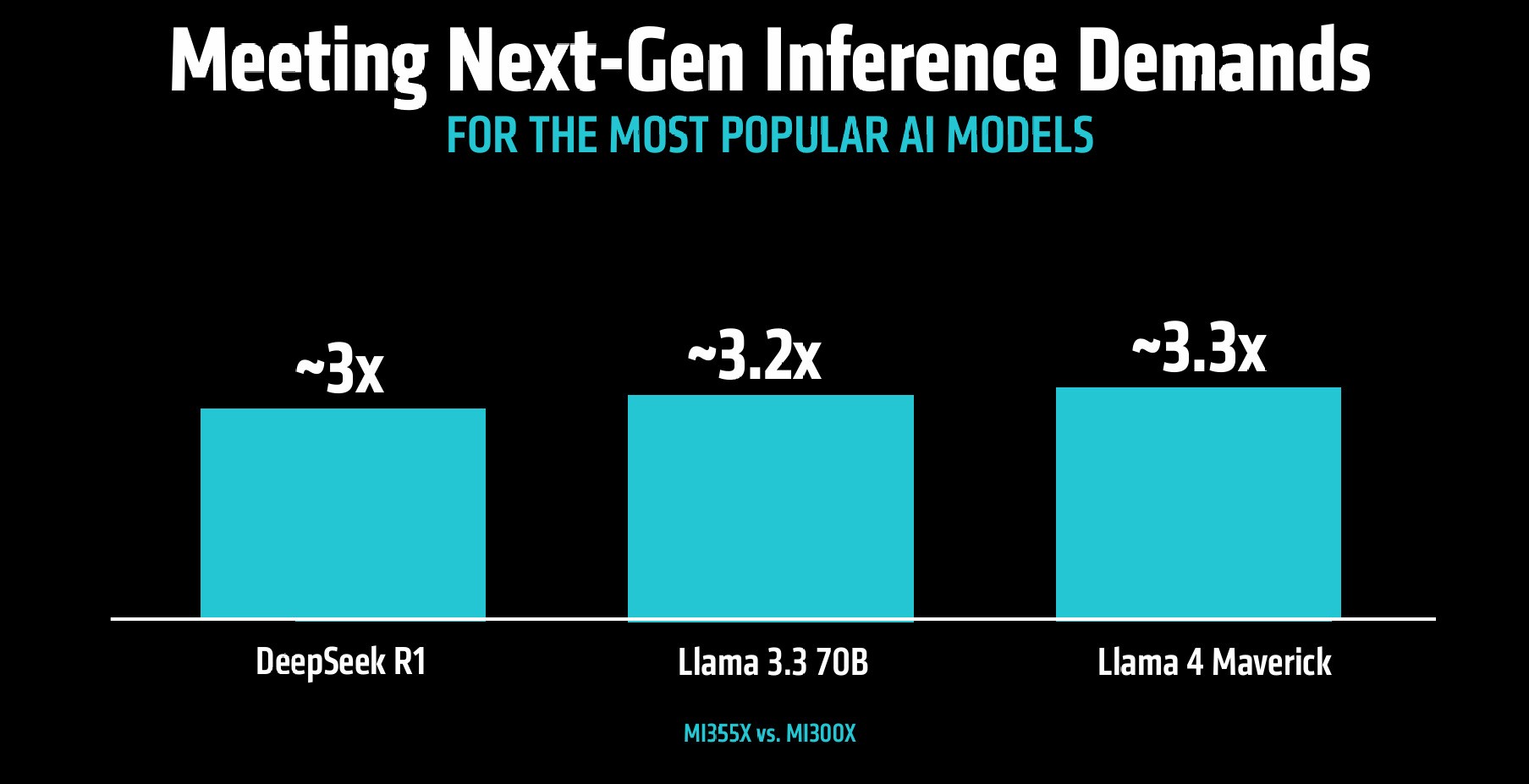
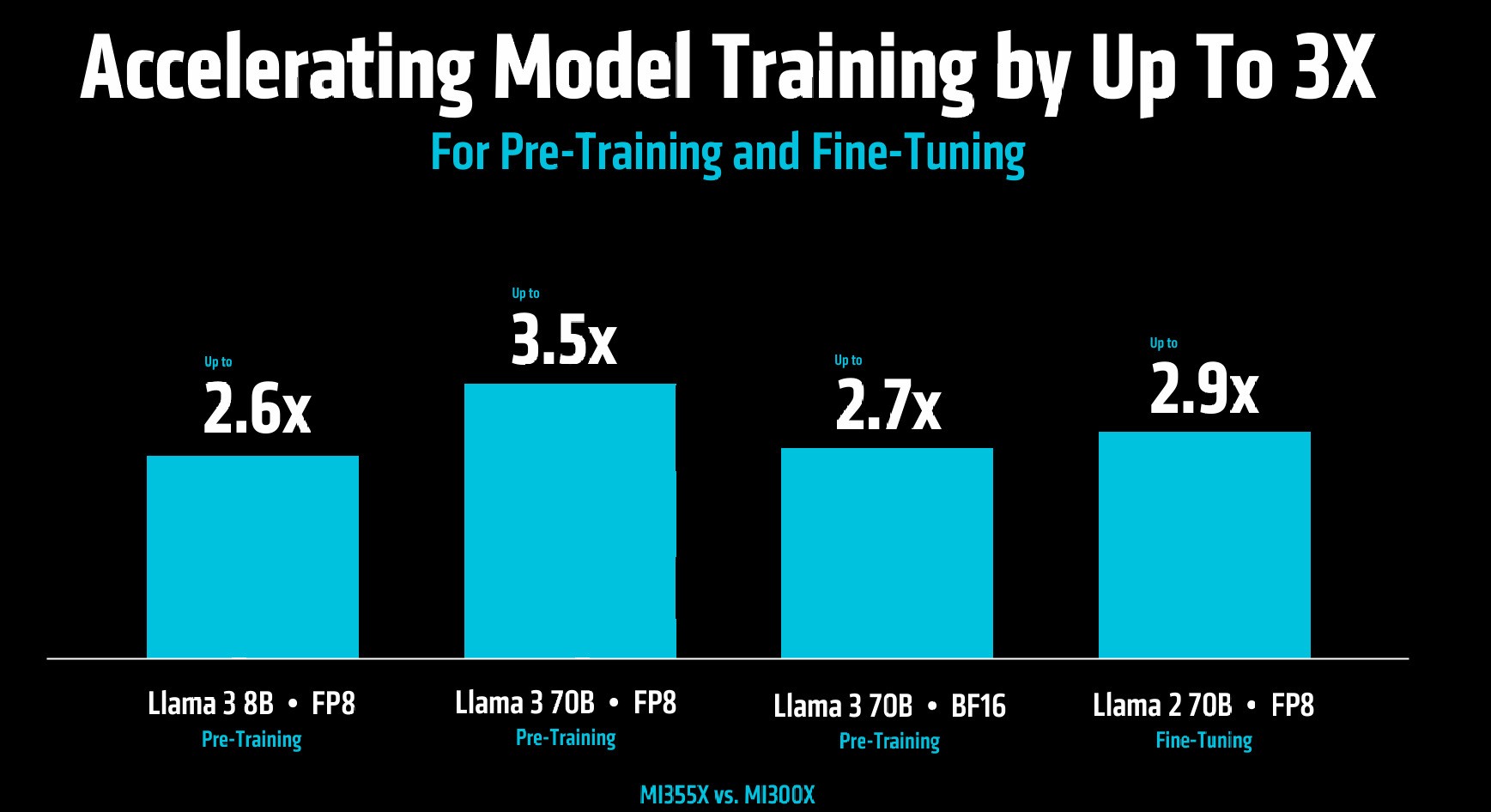
而在大模型训练加速方面,四种不同参数和数据类型的Llama 3/Llama 2大模型预训练速度最低提升2.6倍,最高提升3.5倍,实现训练效率的大幅度代际升级。
此外在与竞品之间的性能差异方面,Instinct MI355X GPU相比NVIDIA GB200/B200而言,在内存容量、内存带宽、各种数据类型峰值性能方面表现都更加出色。

得益于全方位的规格参数领先,Instinct MI355X GPU对比NVIDIA B200/GB200 GPU,在Llama 3 70B/8B大模型预训练速度上与B200持平,而在MLPerf5.0非官方测试结果中,Llama 2 70B大模型微调训练速度上,MI355X GPU比B200快10%,比GB200快13%。

在DeepSeek R1 FP4、Llama 3.1 405B FP4低数据精度、大参数量大模型推理吞吐量方面,MI355X GPU的表现总体更加出色。
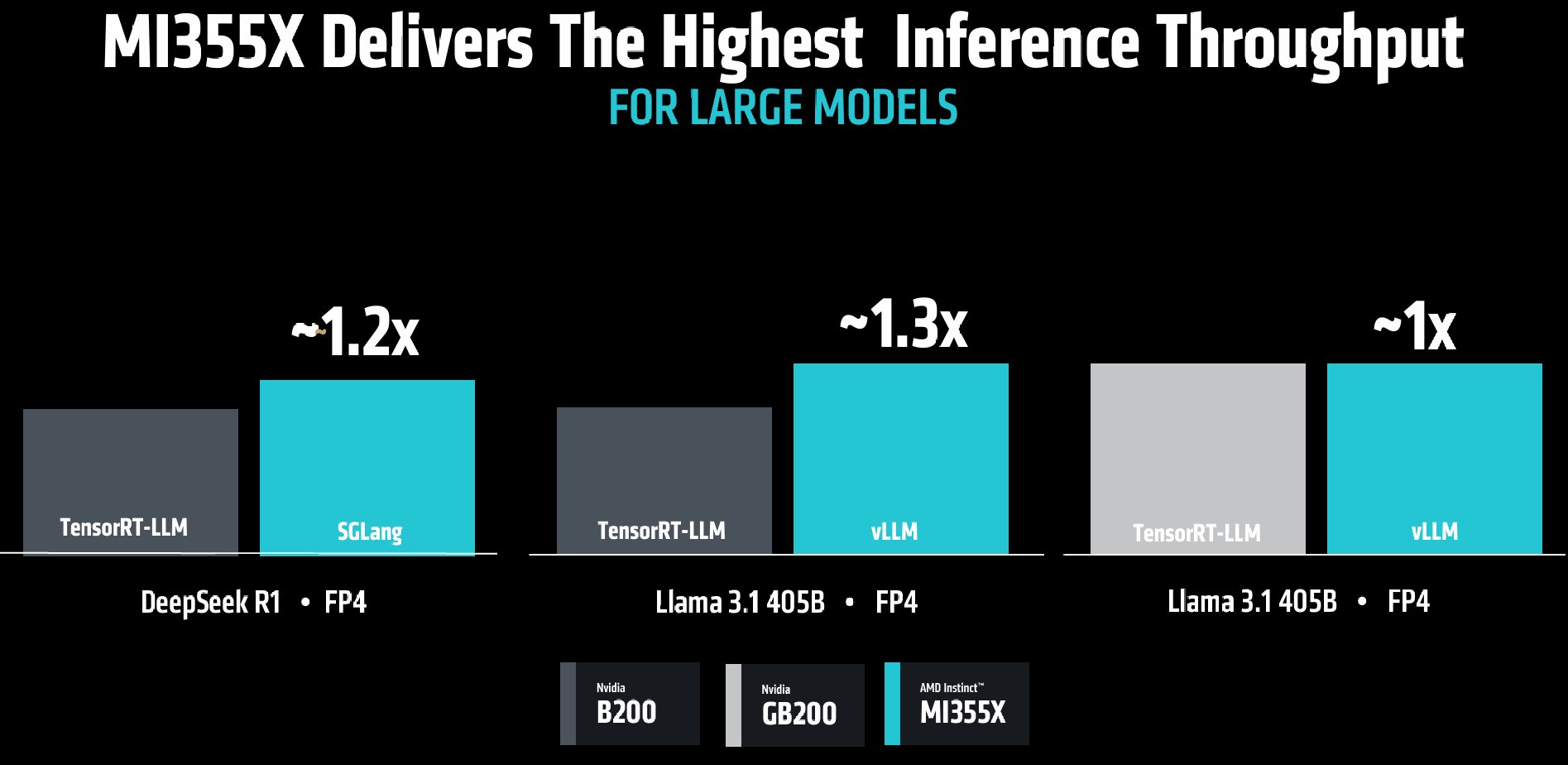
此外,采用AMD Instinct MI350系列GPU解决方案,将获得比竞品更高的经济性,以MI355X GPU和B200 GPU为例,前者可带来超过40%的Tokens/\$成本收益。

接下来附上Instinct MI350系列GPU首发两款产品参数,感兴趣的朋友可以参考:

·生态合作持续发力 为行业带来成熟可靠的全栈式解决方案
基于Instinct MI350系列GPU,AMD与行业生态伙伴持续合作,以第五代EPYC+Instinct MI350系列GPU+AMD Pollara NIC网络解决方案为核心,带来了完全基于开放标准构建的机架基础设施。

AMD Pensando Pollara 400 AI NIC拥有出色的可扩展性设计,它也是业界首款专注于AI领域的智能网卡设备。它支持可编程、支持网络内集合操作,兼容超以太网联盟标准,并拥有高于竞品20%的领先性能体验,高达20倍的大规模扩展能力,10%的集群无故障运行时间提升,以及16%的网络结构成本降低。是值得信赖的高性能、高稳定性、高耐久性、高扩展性专业AI网卡设备。

同时,AMD提供了液冷、风冷的多元化机架可选方案。其中Instinct MI355X GPU主要面向液冷散热方案,可提供128和96个GPU以及36TB和27TB HBM3E内存方案;而MI350X GPU则主要面向风冷方案,提供64个GPU和18TB HBM3E内存方案。

目前,AMD Instinct MI350系列GPU解决方案合作伙伴涵盖了各大主流厂商,如甲骨文、戴尔、SuperMicro、惠普、思科等,且合作将于今年Q3正式开启,届时各家合作伙伴将推出基于AMD Instinct MI350系列GPU打造的AI机架设备。

关于未来,AMD的规划也非常清晰。2026年AMD将推出下一代EPYC+MI400系列GPU以及下一代VULCANO网卡的AI机架,并命名为“Helios”。同时还公布了未来两年基于AMD EPYC “VENICE”以及AMD EPYC “VERANO”处理器的下一代和下下代高性能AI机架解决方案,为未来AI行业的算力发展描绘了更加清晰的前景。



而且在本次峰会上,AMD预先公布了下一代Instinct MI400系列GPU的特性,它将拥有高达40PF和20PF的FP4/FP8算力,并打在432GB HBM4内存,带宽将提升至19.6 TB/s,每个GPU的横向扩展带宽将达到300 GB/s,进一步为AI计算提速。

得益于MI400系列GPU全方位的性能升级,Helios AI机架将具备领先的性能表现,相比采用NVIDIA Vera Rubin解决方案的Oberon机架架构,Helios AI机架内存性能将再度实现大幅领先。

也因此,Instinct MI400系列GPU将为AI计算性能带来巨大飞跃。
·结语
AI时代硬件算力已然呈现出几何式增长趋势,而GPU作为驱动高性能AI算力输出的基础设备,其性能的提升对于AI算力的跃升有着极其重要的意义。
AMD Instinct MI350系列GPU基于全新的CDNA 4架构设计,在内存容量、性能、带宽,GPU执行单元数量、吞吐性能等方面实现了全面进化,并且通过2.5D和3D先进封装技术在更小的芯片面积上实现了晶体管的更高密度集成以及更好的能效表现,从而使得基于MI350系列GPU的AI机架设备能够带来更加出色的综合体验,为AI行业未来的发展注入强劲动力。
此外,AMD预先公布了算力提升惊人的Instinct MI400系列GPU,它将在2026年为整个AI行业的发展再次提速,并在AI大模型计算、训练方面展现出更为惊人的性能实力!
本文属于原创文章,如若转载,请注明来源:算力、能效、内存性能全面升级!CDNA 4架构AMD Instinct MI350系列GPU解析https://diy.zol.com.cn/995/9957434.html