我们期待已久的NVIDIA RTX 30系显卡发布会终于如期而至,21天21年。这21天NVIDIA没有让我们白等,这21年也让我们见证了NVIDIA在计算机图形领域中的辉煌成就。
RTX 3080显卡
NVIDIA这场发布会简短精悍节奏紧凑,满打满算不过40分钟,但NVIDIA CEO黄仁勋先生的每一句话都值得细细品味,乃至反复观看。下面笔者先简短给大家梳理一下发布会的整个流程。
首先为大家整理一下发布会的内容分布:
预热回顾,《堡垒之夜》加入光线追踪。
三个新的工具【NVIDIA Reflex】【NVIDIA Broadcast】【Omniverse Machinima】及电竞显示器发布。
Ampere架构解析及演示
RTX 30系显卡发布




在发布会开场前,作为GeForce特别活动,NVIDIA播放了一段PC游戏的画面发展变革,画框从屏幕中心向外扩散,BGM逐渐增强,最终铺满窗口定格在《赛博朋克2077》,1分钟的简短视频节奏由弱到强,由慢到快,代入感满满。

一次特殊的抗疫
2020年注定是不平凡的一年,新冠病毒正以不可置信的速度席卷全球。在正式演讲前,黄仁勋介绍了全世界一百万名玩家通过GPU来打造分布式计算机,狙击新型冠状病毒,实现了每秒280亿亿次浮点运算能力,并借助超强的处理能力来模拟病毒,最终找到病毒弱点。

《堡垒之夜》加入光线追踪系统
黄仁勋带来的第一个消息是《堡垒之夜》即将支持RTX,我们都知道光线追踪在游戏内分为不同的表现效果,而此次《堡垒之夜》将实现阴影、反射、环境光遮蔽的光线追踪效果,同时该游戏也将支持DLSS 2.0。至于卡通渲染最终添加RTX后的效果是什么样,让我们拭目以待。
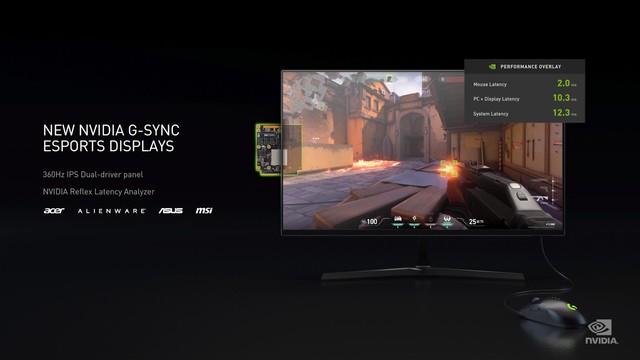
NVIDIA发布 360Hz G-SYNC ESPORTS显示器
在20系显卡中NVIDIA反复提及的“帧能赢”,在此次发布会也做了更进一步的突破,NVIDIA将推出自己的电竞显示器——NVIDIA 360Hz G-SYNC ESPORTS。这款显示器将由Acer、Alienware、ASUS和MSI于今年秋季推出。这款显示器将内置精确的延迟分析工具,可以将系统延迟整体降低至30ms以下。
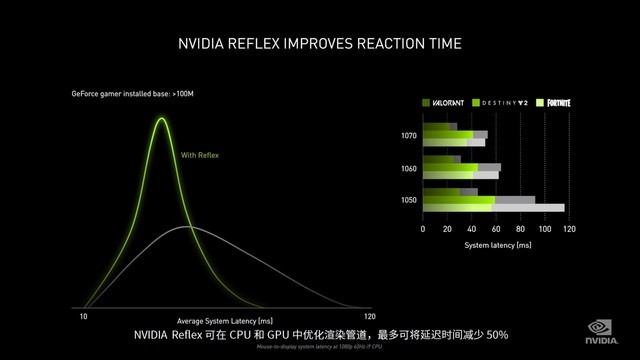
NVIDIA Reflex
除此之外,NVIDIA还将推出全新的电竞技术——NVIDIA Reflex,该项技术可在CPU和GPU中优化渲染管道,极大减少延迟时间。它会随着9月份Game Ready驱动一起推出,目前集成这项技术的游戏有《Valorant》、《堡垒之夜》、《Apex英雄》、《使命召唤:战区》以及《命运2》。
NVIDIA Broadcast
对于游戏主播来说,NVIDIA新推出的Broadcast软件一定会让你感兴趣。这款软件可以让你杂乱无章的房间立即变成直播间,其内置了音频降噪、背景虚化、虚拟背景、头部追踪等功能。NVIDIA Broadcast的工作原理是利用AI算法通过DGX超级计算机深度学习而来,所以既然提到AI和深度学习,那么这款软件的运行基础就是需要在RTX系列的显卡上才能得以应用。
而这款软件的强大之处就在于,主播不再需要任何的背景布置,只需要一个普通的摄像头和一张RTX系列的显卡即可。
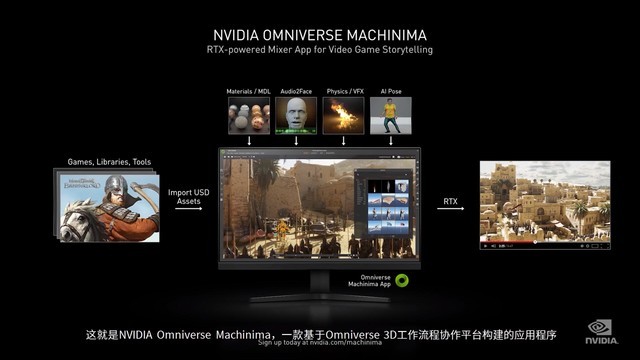
NVIDIA Omniverse Machinima
“引擎电影”对于大部分玩家来说可能还相对陌生,但这正是兴起于游戏中的一种全新艺术形式,相信不久的将来,每个玩家都可以打造属于自己的电影级影片。
Omniverse Machinima是NVIDIA发布的一款引擎工具,该引擎可以精确地模拟光线、实物、材料和人工智能,并且可以适用于大部分第三方设计工具,如3DS、Max、Maya、Photoshop、Epic Unreal和Rhino等,最终使用RTX系列显卡渲染出电影级的效果。这款软件的测试版将在10月推出,用户需单独注册。
对于熬夜看发布会的玩家来说,新的架构和新的显卡显然才是重头戏,在公布新显卡前,黄仁勋先生简单讲解了Ampere架构所带来的变化。
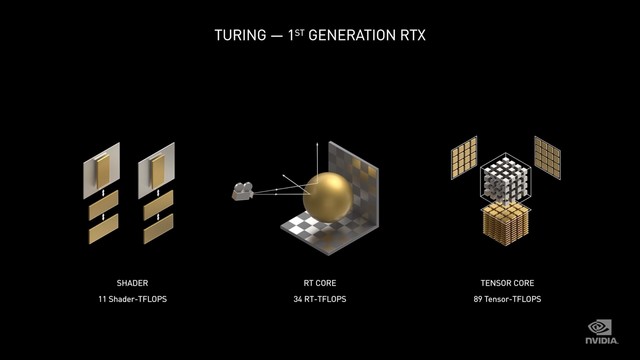
第一代RTX架构 Turing
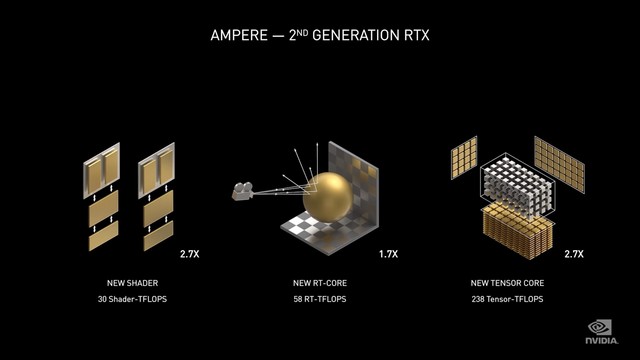
第二代RTX架构 Ampere
相较于初代的Turing RTX架构,Ampere架构在算力上有着成倍的增长,每个时钟执行2次着色器运算,而Turing为1次,着色器性能达到30 TFLOPS,而Turing为11 TFLOPS。
Ampere架构翻倍了光线与三角形的相交吞吐量,RT Core达到58 RT TFLOPS,而Turing为34 TFLOPS。
另外在全新的Tensor Core中,可自动识别并消除不太重要的DNN(深度神经网络)权重,处理稀疏网络的速率是Turing的两倍,算力高达238 Tensor TFLOPS,而Turing为89 Tensor TFLOPS。

芯片说明
全新的Ampere GPU核心拥有280亿个晶体管,基于三星的8nm NVIDIA定制工艺,来自美光的GDDR6X显存,以及我们上面说的,三大处理核心均为初代Turing的两倍速率,构成了有史以来性能最强大的Ampere。
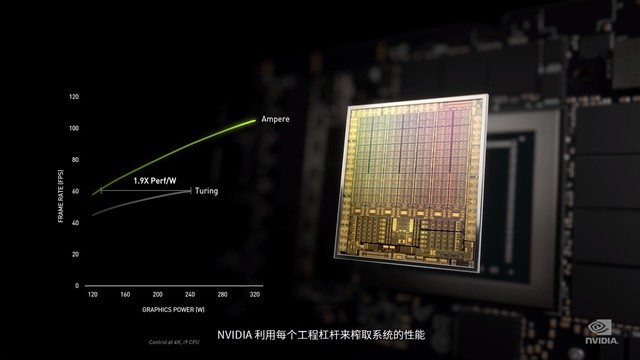
Ampere架构对比Turing架构
Ampere架构相比于Turing架构,性能提升至原来的2倍,能效比提升至原来的1.9倍,这也让搭载Ampere架构的显卡有着前所未有的性能飞跃。
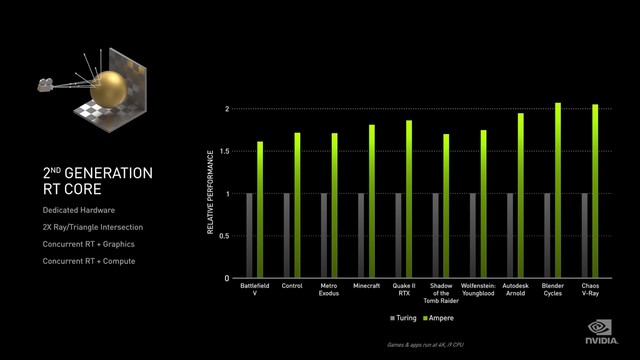
渲染速度提升
在实际测试中,第二代RT Core可以让光线追踪与着色同时进行,进行的光线追踪越多,加速就越快,它将光线相交的处理性能提升了一倍,在渲染有动态模糊的影像时,比Turing快8倍。

使用Quadro RTX 8000实时渲染的Marbles
对于如此快的渲染速度究竟是什么概念,黄仁勋给出了对比,在两个月前的厨房演讲中,展示了完全光线追踪的实时图型Marbles。
当时使用的显卡为 Quadro RTX 8000 专业图形卡,但仅能以720P 每秒25帧来呈现。而今天黄仁勋为我们带来了增强版的夜间Marbles模型,增加了更多光线效果并且还增加了景深效果,最终能以1440P分辨率 每秒30帧来呈现,性能提升了4倍。













演示中的动画完全由光线追踪完成实时渲染,无光栅化处理,并且场景中多达数百个光源,完全没有预烘焙,所以最终呈现在我们眼前的是这样电影级的画质。对于视频的演示效果,笔者只想说,Ampere作为有史以来最大的性能飞跃,毫不夸张。
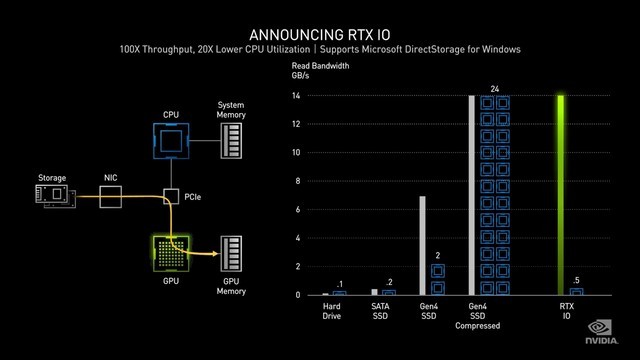
NVIDIA RTX IO
NVIDIA RTX IO可以说是NVIDIA改变电脑运行方式的另一项黑科技,新的RTX IO API可以直接从SSD中快速加载数据并将其流式传输到GPU显存,做到GPU无损解压缩。这中间简化了从存储设备传输数据到GPU显存的流程,极大地减轻了CPU核心的负担,当然作为系统底层的运行方式改变,还需要借助与微软的合作。
RTX 3080显卡

RTX 3080显卡
在发布会的最后一个部分,自然是用户最关心的RTX 30系显卡。黄仁勋先生首先展示的是RTX 3080显卡,从外观上看它采用了非常独特的设计,主动散热的风扇为一前一后,至于这当中有什么玄机,我们接下来慢慢讲。

双轴流式设计
在散热设计上,这次RTX 3080及RTX 3090系显卡采取了革命性的变革,从显卡的内部构造我们也能看出很大区别。它采用了双轴流式设计,空气流量相较于之前的设计增加55%,散热效率提升30%,静音效果提升至3倍。

散热系统示意
具体的工作原理如上图所示,这也是NVIDIA显卡第一次将散热系统与机箱整体散热结合,形成协同工作。
新的散热系统可以吸入外部的冷空气,流经GPU,并将热空气直接从机箱背部排出。另一个背面拉动式风扇同样吸入冷空气,但流经热管上的散热鳍片,并通过机箱整体的散热系统引导至机箱背部排出。

超高密度PCB设计
所以为了搭配新的散热系统,此次采用了超高密度的PCB板设计,前端为“V”字造型,体积较之前缩小了50%
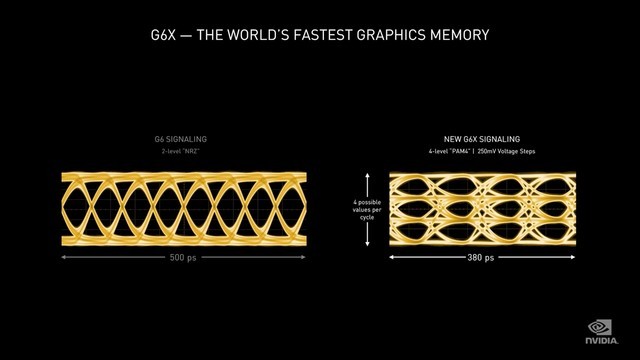
GDDR6X显存
RTX 3080/3090显卡采用的为美光GDDR6X 显存,在单位时间内,GDDR6X显存的数据传输量为GDDR6的两倍。
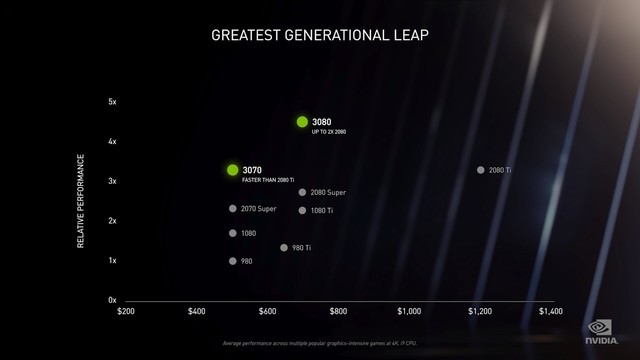
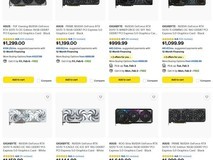
RTX 3080/3070 性能说明
在性能方面,RTX 30系显卡可以说全面超越了20系。RTX 3080的性能比上一代的旗舰RTX 2080 Ti更高,是RTX 2080的两倍,但价格与RTX 2080相同(国内售价为人民币5499元起),可谓加了双倍的量还没有加价。
而RTX 3070显卡的性能同样要比RTX 2080 Ti高一些,但后者的价格为1200美元(约合人民币8200元),RTX 3070的价格仅为499美元(约合人民币3400元,国内售价为人民币3899元起)。

RTX 3090显卡
至于压轴产品RTX 3090则是取代以往的TITAN型号,官方甚至没有给出性能指标,但从图中的8K我们也能猜想到这头“性能怪兽”有多强悍。而事实上,RTX 3090的出现也是首次让玩家能以8K 60帧的画质来流畅体验游戏。
有意思的是,在演讲中黄仁勋还提到,目前仍有很大部分玩家在使用着Pascal架构的10系显卡,其主要原因是因为20系显卡在开启光追后帧数会有严重下降,但基于Ampere架构下的RTX 30系显卡,即便打开光追效果后,游戏帧数也会比10系显卡更高,所有仍在使用10系显卡的玩家,可以放心的升级。
下面为了方便大家查阅这三款显卡的参数及对比,笔者列出了三款显卡的详细参数:
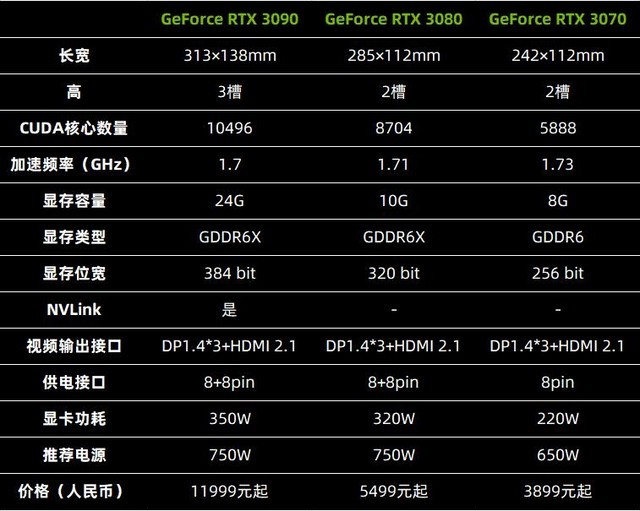
30系显卡综合参数
至此,9月2日00:00的NVIDIA GeForce特别活动圆满结束。在整场发布会中,黄仁勋先生不止一次强调了“这是有史以来最伟大性能提升”。的确,从RTX 30系显卡的性能表现来说,用双倍加量不加价来形容都不为过。作为游戏玩家来说,如果购买RTX 30系显卡,4K60帧的画质才是起步,要知道以往在性能测试中,4K画质基本是天花板的存在,是为了测试显卡性能极限,而刚刚发布的Ampere,则轻轻松松达到了。
同时也有玩家会问,RTX 20系显卡算不算失败的一代,我认为不算。Turing为我们开创了光线追踪和AI学习的新世界,奠定了GPU未来的发展方向,真正意义上实现从性能的堆砌到质的改变。而Ampere则是站在巨人的肩膀,将上一代的路走的更宽更扎实。
好了,以上就是为大家总结的NVIDIA GeForce未来已来发布会全部内容,后续我们也会为大家带来相关显卡的评测内容,请大家持续关注我们的内容。
本文属于原创文章,如若转载,请注明来源:NVIDIA 30系显卡发布会:4K只是起步//diy.zol.com.cn/751/7515063.html