NVIDIA DGX Spark

极摩客EVO X2
一、破局者登场:从机柜到桌面的第一步(1960s - 1970s)
在IBM大型机垄断的时代,"计算机"意味着占地数十平方米、造价数百万美元的庞然大物,只有政府与顶尖科研机构才能问津。1960年DEC公司推出的PDP-1,首次打破了这一僵局——这款配备阴极管监视器的小型机,将体积压缩至单个机柜,价格降至大型机的十分之一,让高校与中型企业首次触碰到计算力量。
1965年问世的PDP-8,被公认为现代迷你电脑的开山之作。它采用精简指令集,重量仅50公斤,售价低至1.8万美元,迅速渗透到工业控制、医疗检测等领域。当时美国麻省理工学院的实验室里,研究员们无需再排队使用大型机,仅凭一台PDP-8就能完成数据运算,这种"即时算力"的体验在当时堪称颠覆性。1970年的PDP-11更是将性能推向新高度,16位架构使其成为首个支持多任务处理的小型机,被美国工业协会评为"70年代最具影响力的技术产品",DEC也借此占据全球迷你电脑市场70%的份额。
二、转型阵痛:微处理器引发的行业洗牌(1970s - 1990s)1971年英特尔4004微处理器的诞生,为迷你电脑埋下了"自我革命"的种子。这款指甲盖大小的芯片集成了2300个晶体管,却实现了以往数十个电子元件的功能,以此为核心的MCS-4微型计算机,将体积缩小至台式机规模,开启了"芯片定义算力"的时代。
随后牛郎星8800、苹果I等个人电脑相继问世,它们以微处理器为核心,价格不足传统小型机的五分之一,直接冲击DEC的市场根基。遗憾的是,DEC固守"小型机优于PC"的理念,拒绝拥抱微处理器技术,其1980年代推出的VAX系列虽性能强劲,却因体积庞大、价格高昂逐渐失宠。与此同时,IBM PC兼容机浪潮席卷全球,迷你电脑的概念开始分化:传统小型机向服务器、工作站转型,而面向个人的小型化计算设备雏形初现。1998年DEC被康柏收购,标志着以机柜为载体的迷你电脑时代正式落幕。
三、萌芽期探索:低功耗技术的暗中蓄力(2000s - 2012)进入21世纪,集成电路工艺进入纳米时代,英特尔Atom、AMD Geode等低功耗芯片陆续问世,配合闪存、微型主板等配件的成熟,现代意义上的"迷你主机"开始萌芽。这一阶段的产品褪去了工业设备的笨重感,却尚未找到大众市场的切入点,主要服务于行业定制场景。
工业领域,研华、控创等厂商推出的嵌入式迷你模块,被用于生产线的实时数据处理,凭借耐高低温、低功耗的优势,替代了传统工控机;教育行业,瘦客户机形态的迷你终端开始普及,通过云桌面技术实现资源共享,降低了学校的设备投入成本。此时的迷你主机更像"幕后工作者",硬件集成度不断提升——CPU、显卡、内存被高度整合在巴掌大的主板上,功耗降至30W以下,但消费者对其认知仍停留在"小众设备"层面,规模化市场尚未形成。
四、大众化破圈:英特尔NUC的市场启蒙(2013 - 2018)2013年英特尔NUC(Next Unit of Computing)的发布,如同一声惊雷,让迷你主机正式走进大众视野。这款仅10x10厘米的主机,搭载赛扬处理器与Sandy Bridge架构,支持用户自行加装内存和固态硬盘,能轻松嵌入显示器背后,完美适配办公、家庭影音等场景。

英特尔通过持续迭代完善产品矩阵:2014年Ivy Bridge版本加入雷电接口,提升外设扩展能力;2015年Skylake架构带来14nm工艺升级,性能与功耗比大幅优化;2018年Coffee Lake架构的第8代产品,将酷睿i7处理器引入NUC系列,使其具备轻度游戏与创意设计能力。
NUC的成功不仅验证了迷你主机的大众市场潜力,更点燃了国内厂商的创新热情——零刻、极摩客等企业纷纷推出NUC型态设计的产品,采用Intel Atom或AMD APU芯片,以2000元以下的价格抢占中低端市场,为国产迷你主机的爆发积累了技术与用户基础。
五、算力革命:AI重构迷你电脑价值(2019 - 至今)2019年后,国产厂商的集体崛起与AI技术的爆发,推动迷你电脑进入"多元竞争+价值重构"的新阶段。联想、零刻凭借高性价比站稳消费市场,而极摩客的横空出世,则以AI算力为突破口,开创了"桌面AI超算"这一全新品类。
2024年成为行业关键转折点:苹果发布Mac mini M4,搭载自研M4/M4 Pro芯片,首次将硬件加速光线追踪技术引入迷你主机,体积压缩至接近Apple TV 4K,多屏显示能力,重新定义了高端迷你主机的标准。2025年年初,极摩客EVO X2与NVIDIA DGX Spark同步亮相,这两款产品的推出,标志着迷你电脑从“生产力工具”正式升级为“桌面AI超算”,更点燃了本地AI计算的激烈战火。
本地AI计算的战火正以前所未有的烈度燃烧。过去,顶级AI算力是少数巨头的专属;而现在,两大极具代表性的产品——NVIDIA DGX Spark与极摩客EVO X2,正以截然不同的姿态,将强大的AI能力带到桌面。一个手握“Blackwell”大杀器,定义专业级新基准;另一个集成“锐龙AI Max+”,化身全能性能猛兽。当1 PFLOP的算力撞上126 TOPS的NPU,当统一内存架构遇上三芯融合,本地AI的未来版图,将如何被它们改写?
(一)核心配置与价格对比:针尖对麦芒的起点在深入探讨之前,我们先将两款产品的核心规格并置,直观感受它们的设计哲学差异。
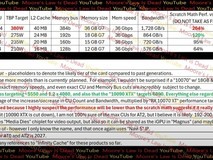
参数 | NVIDIA DGX Spark | 极摩客 EVO X2 |
处理器 | Grace Blackwell GB10(20核ARM CPU + Blackwell GPU),FP4算力 1 PFLOP | 锐龙 AI Max+ 395(16核 Zen5 CPU + RDNA3.5 GPU),XDNA 2 NPU算力 126 TOPS |
内存 | 128GB LPDDR5X 统一内存(带宽 273GB/s) | 128GB LPDDR5X 内存(带宽 256GB/s),显存动态分配最高 96GB |
存储 | 1TB/4TB SSD | 2TB PCIe 4.0 SSD(支持扩展至 16TB) |
价格 | 4TB 版本约 28,917 元 | 128GB+2TB 版本 14,999 元 |
功耗 | 170-240W | 140W 峰值性能 |
操作系统 | DGX OS(基于 Linux) | Windows 11 + Linux 双系统支持 |
● 算力架构之争:DGX Spark的FP4算力专为大模型推理而生,追求极致吞吐,但受限于相对传统的内存带宽。而EVO X2的CPU+GPU+NPU异构设计,在多任务处理和低延迟响应上展现出无与伦比的灵活性,更像是“全能选手”。
● 价格优势凸显:极摩客EVO X2以约52%的价格,提供了在多项关键指标上不遑多让甚至更优的性能,这无疑为本地AI的普及投下了一枚重磅炸弹。
(二)实际AI性能对比:数据不会说谎理论参数终须落地,在实际的AI任务中,两者的表现更是泾渭分明。
1. 大模型推理速度:延迟与吞吐的权衡● DGX Spark:在运行70B参数模型(如Llama 3.3 70B)时,Token生成速度约为5-8 tokens/s。其优势在于理论上的极限,支持单机运行2000亿参数模型,但代价是首次响应延迟较高(约3-5秒),且严重依赖FP4量化压缩,可能牺牲模型精度。
● EVO X2:运行同量级70B模型(如DeepSeek-R1-Distill-Llama-70B)时,Token生成速度达到5.31 tokens/s,而首次响应延迟低至1.02秒,体验优势巨大。更令人惊叹的是,它能以12.24 tokens/s的速度运行235B参数模型,且无需过度依赖低精度量化。在LM Studio等主流工具中,其AI性能较RTX 4090提升2.2倍,功耗反而降低87%。
2. 多任务处理能力:单核专精 vs 全能协作● DGX Spark:虽然支持多模型并行,但受限于内存带宽瓶颈,实际吞吐量并不理想。例如,在图像生成任务中(ComfyUI),其速度仅约1迭代/秒,远低于现代消费级显卡,暴露了其非AI计算部分的短板。
● EVO X2:异构架构的优势在此刻尽显。它可以同时流畅运行文本生成(70B模型)、图像生成和视频处理,资源分配高效智能。其图形性能媲美移动版RTX 4060,支持8K三屏输出,完美契合创意工作流的需求。
3. 延迟与能效比:决定用户体验的关键● DGX Spark:内存带宽瓶颈导致高延迟问题突出,尤其在模型启动时数据迁移耗时明显。实测运行Llama-3.1-8B模型速度仅36 tokens/s,不仅远低于RTX 5090的200 tokens/s,价格却是后者的两倍,能效比堪忧。
● EVO X2:CPU+GPU+NPU的异构架构实现了硬件层面的低延迟响应,首次Token生成时间比DGX Spark快30%-50%。在140W的功耗下实现126 TOPS的算力,能效比极为出色,非常适合需要长时间稳定运行的本地推理任务。
(三)软件生态与扩展性:易用性与未来的博弈硬件是基础,软件和生态决定了你能走多远。
1. 软件兼容性:封闭花园 vs 开放世界● DGX Spark:强依赖NVIDIA专属软件栈(CUDA、TensorRT-LLM),虽然强大,但其ARM架构导致部分成熟的x86工具链需要转译或虚拟化,兼容性受限。仅支持Linux系统,无法直接运行海量的Windows应用。
● EVO X2:完全拥抱成熟的x86生态,无缝支持Windows 11原生AI工具(如LM Studio、Amuse 3.0)和所有主流框架。提供的双系统选项,让用户可以在Windows的便捷与Linux的专业开发之间自由切换。
2. 扩展性:集群之梦 vs 桌面现实● DGX Spark:通过NVLink-C2C和ConnectX-7网卡支持双机集群,内存可扩展至256GB,为超大型模型微调提供了可能。但集群成本高,这使其注定是少数顶级实验室的“玩具”。
● EVO X2:提供了极为实用的扩展性,支持双M.2 SSD扩展(最高16TB)和内存升级,满足本地数据集存储需求。其仅1.5L的娇小机身,便于部署在任何边缘或移动场景。
(四)适用场景与性价比结论:谁是你的最优解?基于以上分析,我们可以清晰地勾勒出两款产品的理想用户画像。
强烈推荐选择极摩客 EVO X2,如果你是:
● 本地AI开发者与推理用户:需要高效部署70B-235B参数模型,进行实时对话、代码生成、图像创作等,其性价比远超DGX Spark。
● 创意与生产力专业人士:工作流涉及视频剪辑、3D渲染、AI辅助设计,需要强大的图形性能和成熟的Windows生态。
● 小型企业与个人用户:预算有限,但渴望拥有高效、私有化的AI算力,以避免云端依赖和数据隐私风险。
仅在以下极端场景推荐选择 DGX Spark:
● 超大型模型前沿研究:你的工作核心是运行和探索2000亿参数以上的模型(如GPT-4级别),且有充足的预算和集群扩展需求。
● 需要与NVIDIA DGX云/数据中心无缝迁移的专业AI实验室。
最终性价比结论:极摩客EVO X2以52%的价格,实现了80%以上的AI性能,尤其在延迟敏感型任务(如实时客服、医疗诊断辅助)中表现更优。DGX Spark的价值在于其对超大模型的极限支持,但用户需要为这种专业场景支付高昂的溢价,对于绝大多数用户而言,这笔投资难以回本。
大模型推理性能
AMD锐龙AI Max+ 395平台胜出
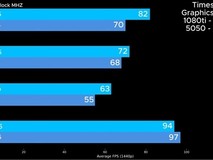
在AI推理性能方面,可能大家一直有一个偏差:NVIDIA的解决方案硬件规格亮眼,认为其必然在性能上占据优势。然而实际情况有点让人大跌眼镜。除了前Oculus VR首席技术官约翰·卡马克的吐槽,目前国外众多媒体已经对NVIDIA DGX Spark进行了详细的评测,我们引用YouTube科技博主Bijan Bowen的测试数据来具体分析。
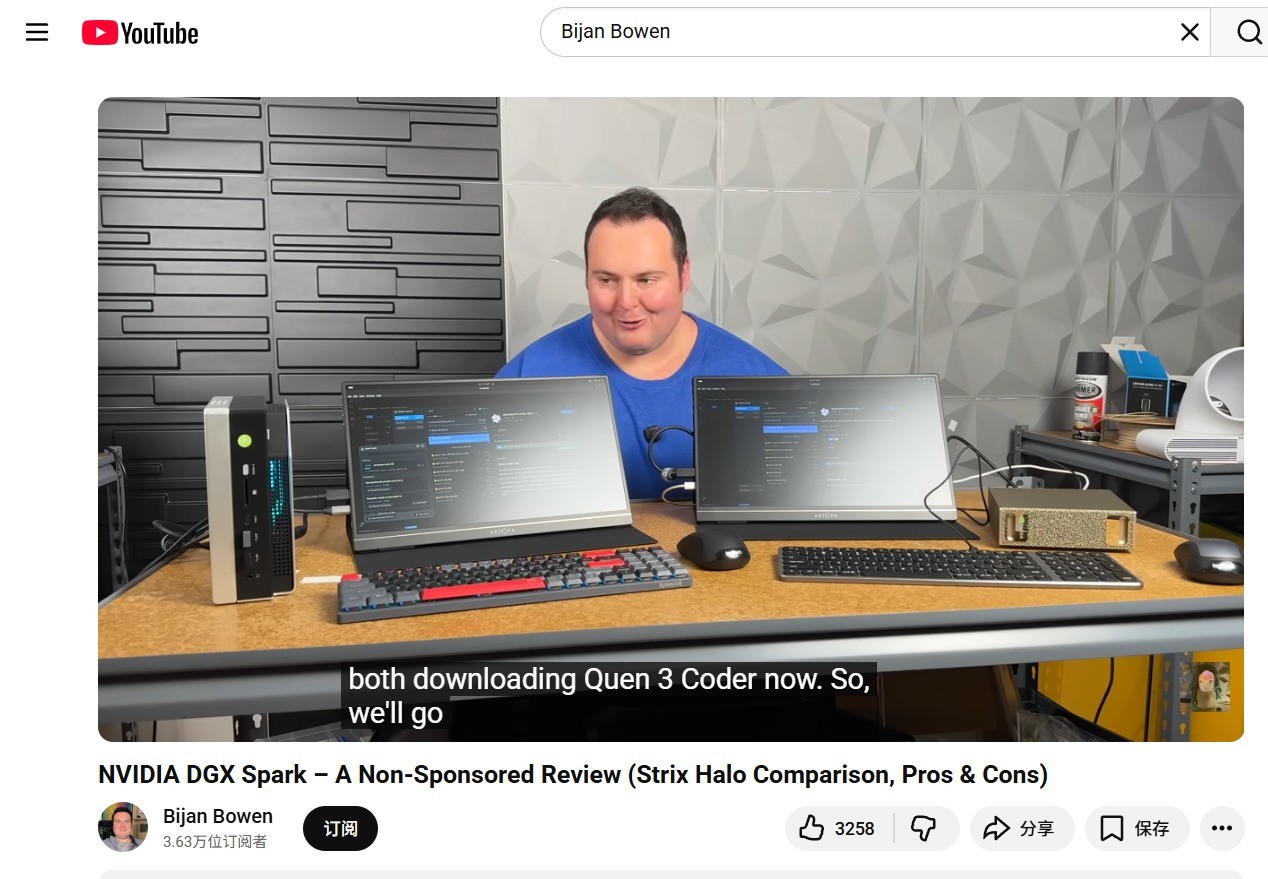
▲YouTube科技博主Bijan Bowen对NVIDIA DGX Spark和AMD锐龙AI Max+ 395平台进行了详细测试。
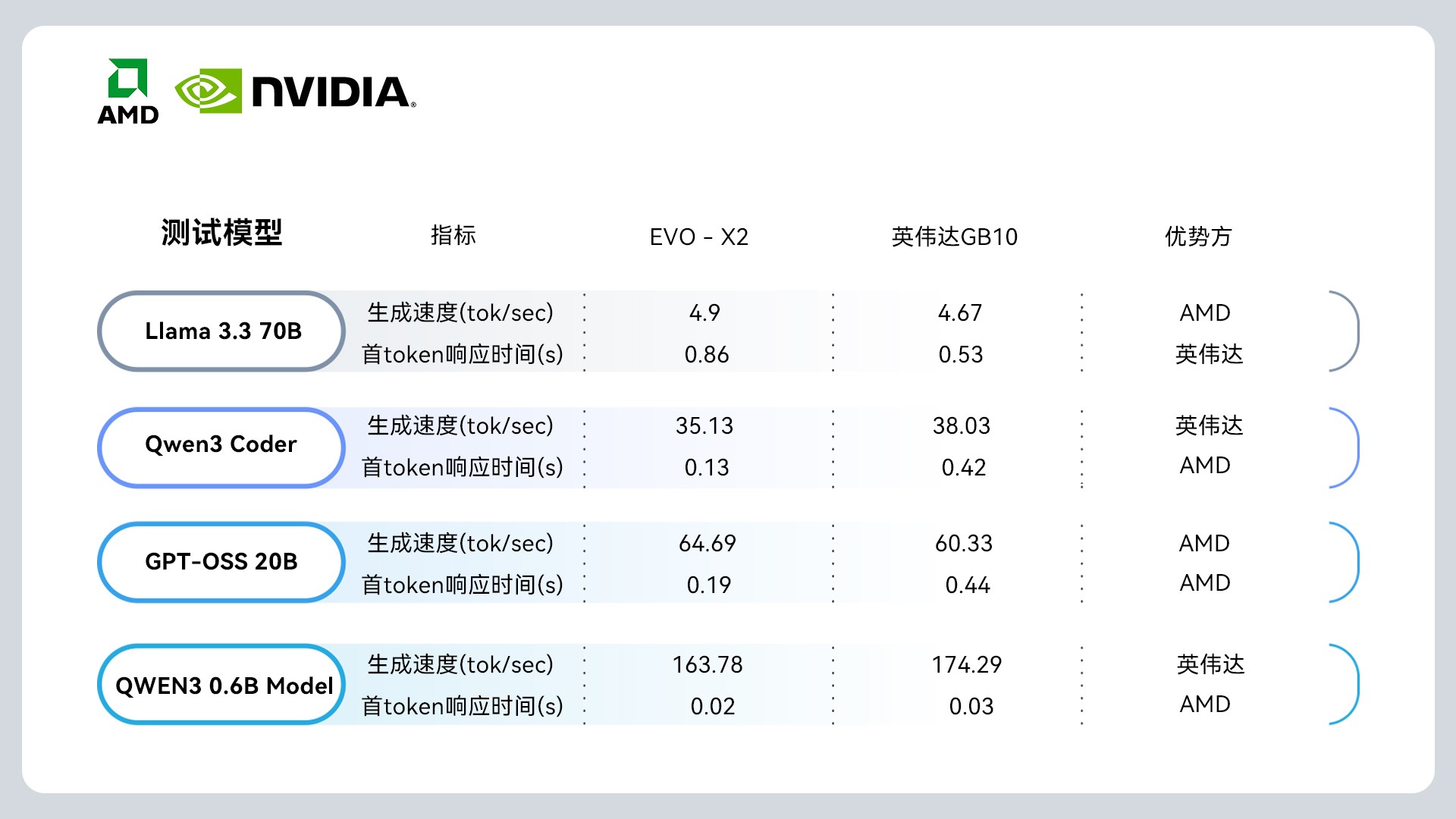
Bijan Bowen不久前对NVIDIA DGX Spark和AMD锐龙AI Max+ 395平台做了详尽的对比测试。测试环境严格控制变量,两台机器均配备128GB统一内存,运行相同的模型和提示词。在本地大模型测试中(Llama 3.3 70B),AMD锐龙AI Max+ 395平台的推理速度为4.9 tokens/s,而NVIDIA DGX Spark的推理速度仅4.67 tokens/s,相比之下AMD平台领先大约5%。
在GPT-OSS 20B模型测试中,这两个平台的性能差距更加明显。AMD锐龙AI Max+ 395平台的推理速度达到64.69 tokens/s,而NVIDIA DGX Spark只有60.33 tokens/s,相比之下AMD平台领先大约7%。在Qwen3 Coder 30B模型测试中,NVIDIA DGX Spark扳回一城,以38.03 tokens/s的速度略微领先于AMD锐龙AI Max+ 395平台的35.13 tokens/s。
从以上测试成绩能够看出,在本地部署大模型时,AMD锐龙AI Max+ 395平台相比NVIDIA DGX Spark拥有更快的响应速度和更流畅的用户体验。AMD锐龙AI Max+ 395平台采用独特的统一内存架构,支持高达128GB LPDDR5x 8000内存,其中最高96GB可分配给GPU作为专属显存。在实际的大模型推理场景中,AMD平台的显存分配策略也让其在应对不同参数规模的模型时具有更高的灵活性。
▲NVIDIA DGX Spark
实际上NVIDIA DGX Spark搭载NVIDIA GB10 Grace Blackwell GPU和128GB内存,NVIDIA官方宣称其能提供高达1 PFLOP(1000 TOPS)的AI算力,但是它在大模型上的表现却与宣称的AI算力不符,背后的原因可能是与其大型产品GB200和GB300不同,GB10没有使用超高速HBM内存,并且受功耗和成本限制,NVIDIA选择了时钟频率为9400MT/s的LPDDR5X内存。与CPU芯片的256位内存总线连接后,GB10最高可提供273GB/s至301GB/s的带宽。而内存带宽是推理性能的关键指标——内存速度越快,芯片输出Token的速度就越快。使用LPDDR的决定表明英伟达在内存容量和带宽之间做出了明显的妥协。
上文引用《微型计算机》报道
(五)总结:AI普及化的浪潮之巅这场对决的结果,比许多人预想的要清晰。极摩客EVO X2凭借更低的价格、更灵活的异构计算架构和更成熟的软件生态,已然成为AI桌面超算的性价比标杆。其126 TOPS的算力和128GB的巨大内存,足以从容应对当前绝大多数本地AI任务。而NVIDIA DGX Spark,则像一座矗立在云端的灯塔,指引着AI算力的终极方向,但其高昂的身价和特定的适用场景,使其更像是一个象征性的存在,而非大众化的选择。对于追求高效、低成本AI部署的开发者、小型企业和科技极客而言,答案已经不言而喻。在AI普及化的浪潮之巅,极摩客EVO X2无疑是那个更务实、更明智的选择。
2025年,行业迎来新的技术里程碑——极摩客在重庆英特尔技术创新大会上,全球首发搭载英特尔18A工艺的EVO T2主机。这款基于Panther Lake平台的产品,采用英特尔酷睿Ultra 388处理器,凭借全环绕栅极晶体管与背面供电技术,实现180 TOPS AI算力,支持128GB LPDDR5X内存与16TB存储扩展,计划2026年一季度上市。从4004芯片的2300个晶体管,到18A工艺的万亿级晶体管密度;从DEC PDP-1的机柜体积,到EVO T2的手掌大小,迷你电脑用50年时间证明:计算的未来,在于将更强大的算力,封装进更小巧的形态中。
如今,极摩客产品已行销全球70多个国家,日本亚马逊迷你电脑品类销量前十中占据七席,美国亚马逊入围五款,中国智造正以桌面AI超算为载体,在全球迷你电脑市场书写新的篇章。
本文属于原创文章,如若转载,请注明来源:从机柜到桌面AI超算:迷你电脑50年进化史https://diy.zol.com.cn/1096/10960372.html