本次RTX 4090和RTX 4080的发布网上已经有不少信息,除了已经公布的规格参数和售价外,NVIDIA还召开了特别的媒体培训会,详细讲了关于架构、Omniverse以及一些测试工具的使用方法。
首先按照惯例科普一下架构,我们先从Ada Lovelace这个人讲起,相较于Ampere,这位似乎大家更陌生一些。
01 Ada Lovelace(1815-1852)
Ada Lovelace是英国数学家、计算机程序创始人,建立了循环和子程序概念,被称为世界上第一位程序员。
Ada从小对数学有极高天赋,其父称她为“平行四边形公主”,后来的合作伙伴Charles Babbage称她为“数字女巫”。在19岁时Ada嫁给了自己曾经的科学家庭教师,婚后的她对数学热情不减。
1842年到1843年花了9个月时间翻译了Babbage的《分析机概论》的备忘录,写了很多注记,其中给出了用计算机进行Bernoulli数求解的详细说明。由此,Ada被广泛认为是世界上第一个程序员。
而以她名字命名的语言——ada语言,已经成为了美国军方开发战斗机等尖端武器的语言。
从几行简短的生平简介中,不难看出Ada的生命虽然只经历了短暂的37个春秋,但却足以被后人铭记。
这也是为什么此次NVIDIA RTX 40的先行宣传中,用到了“以未来敬传奇”的slogan,下面我们详细剖析一下,这次的Ada Lovelace除了性能,还有哪些创新和超越。
02 Shader
NVIDIA Ada Lovelace架构采用了定制的TSMC 4N工艺,完整的核心拥有760亿的晶体管,而NVIDIA Ampere架构为280亿个。
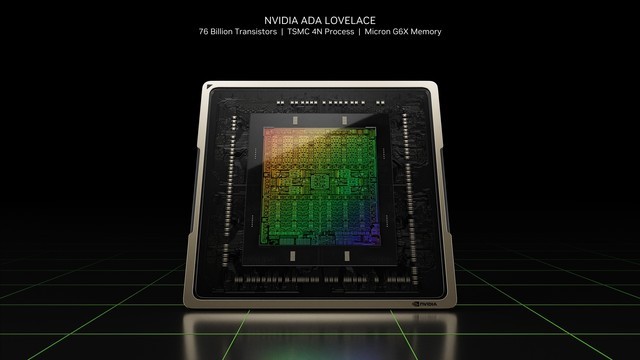
与上一代NVIDIA Ampere相比,NVIDIA Ada Lovelace在相同功率下,具有2倍以上的性能提升。最高可达到90-TFLOPS的着色器数据吞吐量,而本次发布的GeForce RTX 4090则达到83-TFLOPs,相比上一代NVIDIA Ampere则只有40-TFOPs。
Shader Execution Reordering (SER)着色器执行重排序
SER主要的作用是提升着色器性能,它可以将效率低下的工作负载,动态重组为更高效的工作负载。主要针对光线追踪的性能提升非常大。
简单地说,GPU在执行类似工作的时候效率最高。但随着光追效果越来越强大,每个场景可能有数百万条光线照射在不同材质上,而我们知道不同材质的反射率,以及反射效果也是不同的。所以这样就为着色器创建了大量的、发散的,效率低下的工作负载。
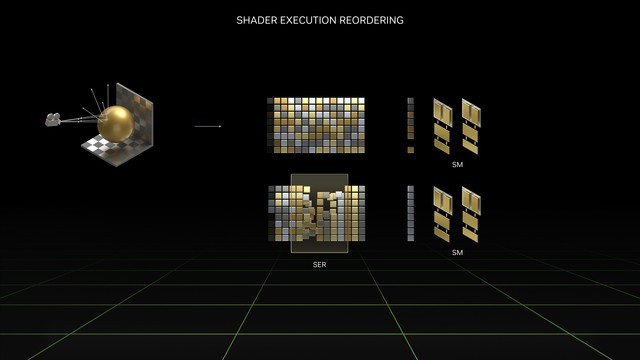
SER则可以将这些杂乱的指令重新分门别类,动态重组为更高效的工作负载。根据NVIDIA的说法,SER可将着色器性能最多提升2倍,并将游戏帧率最高提升25%。
不过好在SER并不是RTX 40系的专利,它是一个易于集成的SDK,目前需要游戏开发商集成在游戏中。不过由于它是一个通用的逻辑,后续也有可能直接集成在Windows的API中,这样游戏开发者就无需特意引用,直接调用系统API即可。

可以说SER对于手持RTX 20系及以上(能够开启光线追踪)的N卡用户来说,是极大地福音。毕竟免费提升的光追性能,谁不喜欢呢。
03 第三代RT Cores
RT Core的作用在于更快的光线追踪计算能力,如果说在RTX 30系显卡中,想要畅享4K高帧率游戏有点吃力,那么RTX 40系显卡中,将显得轻而易举。
在GeForce RTX 4090这张显卡上,达到了191 RT-TFLOPs的处理能力,而RTX 30系显卡最快处理能力为78 RT-TFLOPs,足足为2.4倍。并且根据NVIDIA的官方说法,第三代RT Core的峰值RT-TFLOPs相比于前代提高了2.8倍。而这只能说明,这张4090并非Ada Lovelace架构的最终形态。
Opacity Micro-Map Engines
另外在第三代RT Cores中引入了两个重要的硬件单元,首先是Opacity Micro-Map Engines,可以译为微映射透明度引擎,它主要的作用是优化光线追踪渲染,可大幅减轻着色器的工作负担。
比如树叶之类的复杂物体,不同的光线都会影响它的表现状态,以及树叶之间的光线反弹,所以对于光线追踪的计算量是巨大的。
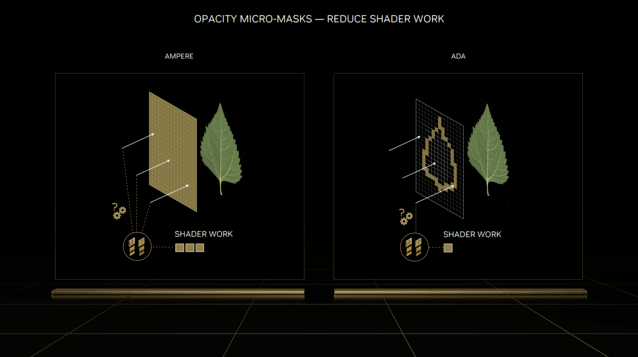
不过Opacity Micro-Map Engines可以将光线追踪特性烘焙到不透明蒙版中,所以那些不规则形状和半透明的对象,也就能够更快更精准的渲染出来,从而极大减轻着色器的工作负担。
Displaced Micro-Mesh Engines(DMM)
Displaced Micro-Mesh Engines可译为微网格置换引擎,它构建光线追踪的BVH(Bounding volume hierarchy)的速度提高了10倍!所使用的的显存减少了20倍!

DMM由第三代RT core本地处理,与前几代相比,它只使用基本三角形渲染复杂几何图形,极大减少了存储和处理需求。
具体的工作原理从图中一目了然,新的DMM可以将面数非常多的复杂图形做简化,创造出简单的模型,但整体的光线追踪效果不变。

通过一些模型数据我们可以具体看到,新的DMM将模型简化了多少。原本1100万三角面的模型,经过简化后,只有15万左右的微网格,BVH的构建速度提升了8.5倍,小了6.5倍。
而这还不是最夸张的,越复杂的模型往往优化的效果越好,在官方展示的这几组对比示例中,最快可提升大于15倍的速度,容量简化20倍的模型。
04 第四代Tensor Cores
除了光追单元的升级外,第四代张量核心的升级更加恐怖。它采用了新的FP8张量引擎,在GeForce RTX 4090这张显卡上,吞吐量达到了1.32 Tensor petaFLOPs,提高了5倍。
注意这里的单位——petaFLOPs。以往的TFLOPs为万亿次浮点运算,而petaFLOPs则为千万亿次浮点运算。
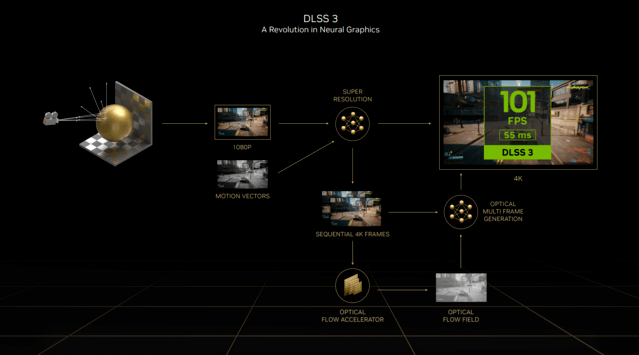
DLSS 3
本次推出的DLSS 3也是RTX 40系一大卖点,从DLSS 2.3直接迈入了3.0版本,也能看出此次的升级之大。而DLSS 3也被NVIDIA官方称为神经网络渲染新时代。
全新的DLSS 3在原有的DLSS超分辨率的基础上,添加了光学多帧生成技术,以生成全新的帧,而不像原来只能生成像素。
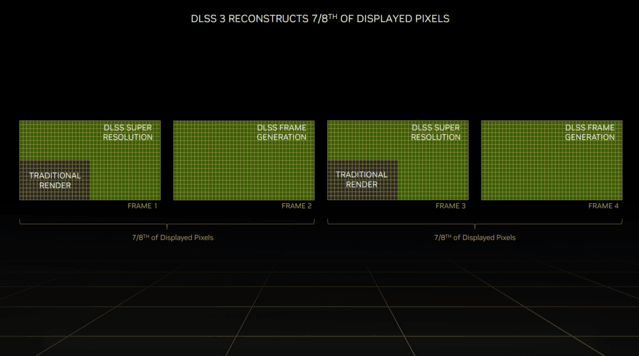
DLSS 3结合了DLSS超分辨率、DLSS帧生成和NVIDIA Reflex这三大技术,能够重建八分之七的像素,极大提高性能。
在GPU受限的游戏中,比如2K分辨率及以上的更高分辨率,DLSS 2能够将帧率提高2倍,DLSS 3则能够提升4倍。
New Optical Flow Accelerator
New Optical Flow Accelerator光流加速器是在第四代Tensor Cores中最新引入的,这也是为何DLSS 3中的帧生成为RTX 40系显卡独享。
光流加速器在原本DLSS 2的基础上,还可以计算两个连续帧内的光流场,能够捕捉游戏画面从第1帧到第2帧的方向和速度,从中捕捉粒子、反射和光照等像素信息。并分别计算运动矢量和光流来获得精准的阴影重建效果。

以《赛博朋克2077》为例,在第一帧,光流加速器会捕捉到每一个像素中的粒子、反射和光照等信息。并在第二帧中查找匹配的像素区域,计算帧之间的差值。
如果说原来DLSS 2能够“猜”出一张图剩下的像素,那么DLSS 3除了这些,还能够“猜”出下一帧的画面。
另外由于DLSS 3的帧生成是在GPU中处理和运行的,所以即使遇到CPU瓶颈的游戏,AI同样能够提升帧率。这也是为什么在此次发布会中说到,DLSS 3能够突破CPU的限制来提升帧数。

05 In total
总之,本文介绍的也只是Ada Lovelace架构中比较大的改变,第三代RTX架构还有很多升级,如双AV1编码器、RTX Remix以及Ada内核的变化等等,这些我们等到首测解禁会为大家一一奉上,详情请关注10月11日晚9点的RTX 4090首测。
本文属于原创文章,如若转载,请注明来源:RTX 40系Ada Lovelace架构详解 4倍提升哪来的?https://diy.zol.com.cn/802/8029758.html