架构:为AI设计的Tensor单元
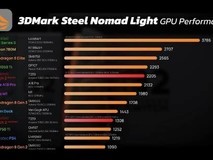
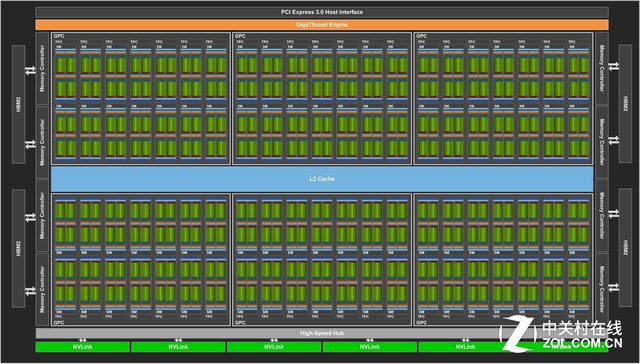
从架构整体设计上看,Volta核心同Pascal和Maxwell一样,采用了6组GPC的设计,只不过是每组GPC内的SM单元呈递进式增长:Maxwell每组GPC的内部有8组SM单元,Pascal增加到10组,而最新的Volta则是增加到14组。有一点需要说明,由于单双精度比的不同,GP100核心每组SM单元内的CUDA核心数量与GP102是不同的,前者为64个,后者为128个,所以我们只看GP100。
GV100核心架构图
GV100同GP100每组SM单元内的CUDA数量一样,均为64个,而CUDA处理器的总数理应为64*14*6=5376个,但GV100核心的CUDA处理器数量为5120个,少了的256个正是因为NVIDIA关闭了4组SM单元,这一做法同GP100如出一辙。
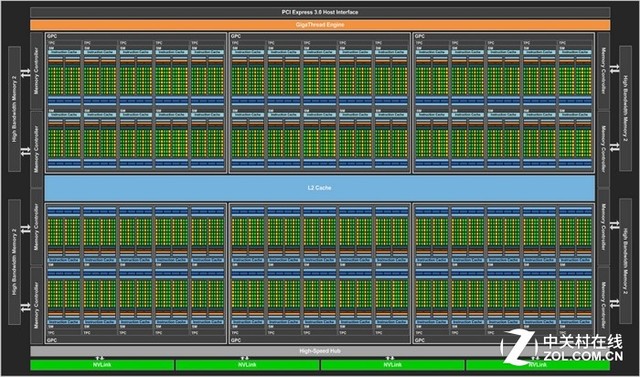
GP100核心架构图
前面说到的64是FP32单精度运算单元数量,在单双精度单元数量比上,GV100同GP100一样为2:1,也就是说每组SM单元中有32个FP64双精度单元,理论值应为32*14*6=2688个,但由于关闭了4组SM单元,所以总数为2560个。
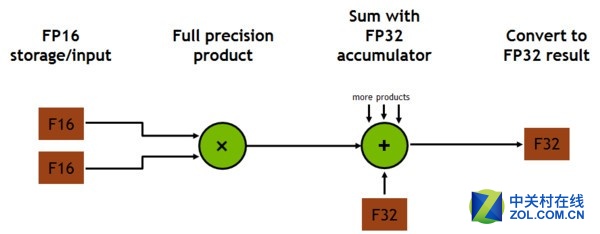
Tensor单元工作流程图
由于NVIDIA现在已经转型为一家AI公司,因此其GPU产品也开始着力于AI、DP等领域的优化发掘,在Pascal中NVIDIA开始强调FP16半精度,因为深度学习对精度的要求并不高,甚至FP8就够了,其更需要的是更强大的运算性能。在Volta中,NVIDIA带来了革命性的Tensor运算单元,该单元是继FP16和FP8后为AI设计的全新利器。其能够提供高达120 TFLOPS的超强运算性能,而且效率高且非常省电。

V100中SM单元设计
在GV100核心中,每组SM单元中包含8个Tensor单元,其能够提供高达120 TFLOPS的超强运算性能。相比于在P100的FP32单元上,Tesla V100的深度学习训练能力是前者的12倍,而相比于在P100的FP16单元的深度学习推理能力上,V100是前者的6倍。
本文属于原创文章,如若转载,请注明来源:12倍于上代的DP性能 NVIDIA Volta架构解析//diy.zol.com.cn/639/6393294.html