性能:DP方面能力提升迅猛
由于Volta同Pascal相比架构仅仅是小幅改动,因此V100的理论性能提升同P100相比仅仅是规格增加而带来的,但实际运行方面,其提升还是相对可观的,尤其是人工智能和深度学习能力。首先我们来看一下在HPC运算方面的性能提升:
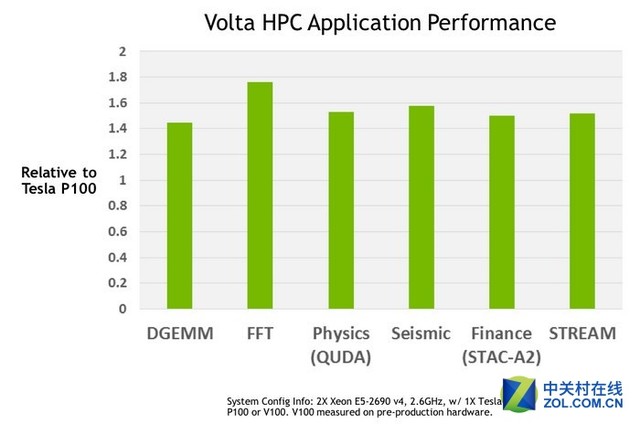
Volta HPC应用性能提升
官方给出了V100与P100在6款HPC应用中的性能对比,其中最低增长了42%左右,最高增长了76%左右,平均提升幅度约为50%,可见提升还是比较明显的,但我们也能看出,由于V100的频率与P100基本相当,所以实际性能并没有从M40到P100那种翻天覆地的提升。接下来我们看看Tensor单元的引入会对V100的深度学习性能带来怎样的影响:
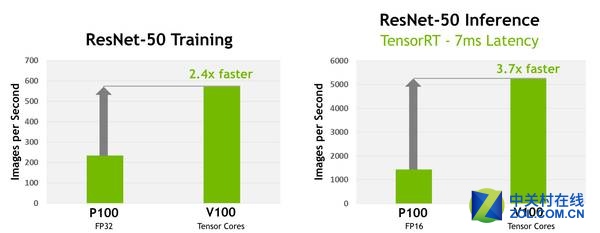
ResNet-50深度神经网络训练任务中的速度对比
从图中可以看出,Tesla V100使用Tensor单元在ResNet-50深度神经网络训练任务中的速度是Tesla P100使用FP32单元进行运算的2.4倍;如果每张图像的目标延迟是7ms,那么Tesla V100使用Tensor核心在ResNet-50深度神经网络进行推理的速度是使用FP16单元的P100的3.7倍(参与测试的V100为原型卡)。
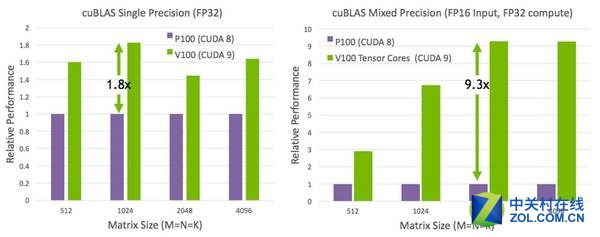
Tesla V100 Tensor单元和CUDA 9对GEMM运算的性能提升
矩阵-矩阵乘法运算(BLAS GEMM)是神经网络训练和推理的核心,被用来获得输入数据和权重的大型矩阵的乘积。从上图我们可以看出,相比于基于Pascal的GP100,Tesla V100中的Tensor单元把这些运算的性能最高提升了8倍多。
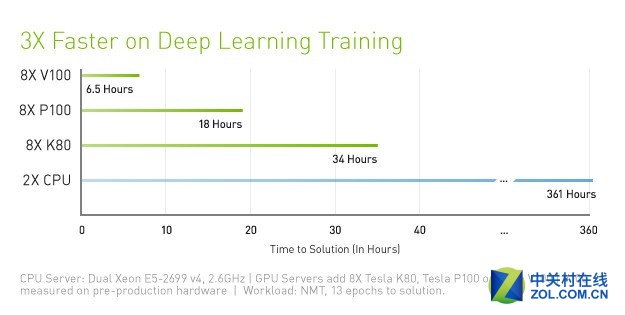
不同平台深度学习训练时间对比
还是得益于Tensor单元强大的实力,8路V100的深度学习训练时间仅为8路P100的三分之一左右,而双路E5 2699V4的耗时是8路V100的56倍,这种差距是非常悬殊的。
以上就是Volta架构分析的全部内容,其主要特性无非为三点:1、史上最大规模的GPU;2、首款采用12nm工艺的GPU;3、全新加入的Tensor单元让GV100的DP性能达到了史无前例的新高。在GTC 2017大会上,老黄表示NVIDIA在研发Tesla V100的过程中投入了30亿美元的巨资,这是迄今为止NVIDIA投资的最大的单个项目,比Pascal还多花了10亿刀。这30亿刀让NVIDIA整整领先了AMD一代,AMD这边甭说Navi,就连Vega也迟迟不见踪影,正是如此,NVIDIA在下半年还不准备放出消费级的Volta,就让我们期待明年初的消费级Volta吧,4K被彻底征服不是梦。
本文属于原创文章,如若转载,请注明来源:12倍于上代的DP性能 NVIDIA Volta架构解析//diy.zol.com.cn/639/6393294.html