去年四季度,英特尔推出的新一代“Battlemage”锐炫B580桌面级显卡获得了不少好评,在2000元价位段形成了超高的性价比优势,帮助英特尔GPU获得越来越多的市场和用户认可。
其实除了消费级产品线之外,英特尔GPU也拥有面向企业级、工作站以及AI领域的专业级显卡,即锐炫Pro。今天,英特尔正式带来了锐炫Pro系列的两款新品:锐炫Pro B50和锐炫Pro B60。前者面向图形工作站,后者面向AI推理工作站。


下面我们看看两款锐炫Pro系列新品的核心特性。
锐炫Pro B50系列拥有16个Xe-Cores,16GB显存,带宽224GB/s,集成128个XMX矩阵计算引擎,INT8算力达到170TOPS,功耗为70W,支持PCIe5.0。同时它有着出色的能效比,外形采用标准双槽设计,支持消费及Pro版驱动,支持主流ISV认证,并且同时支持Windows与Linux系统。

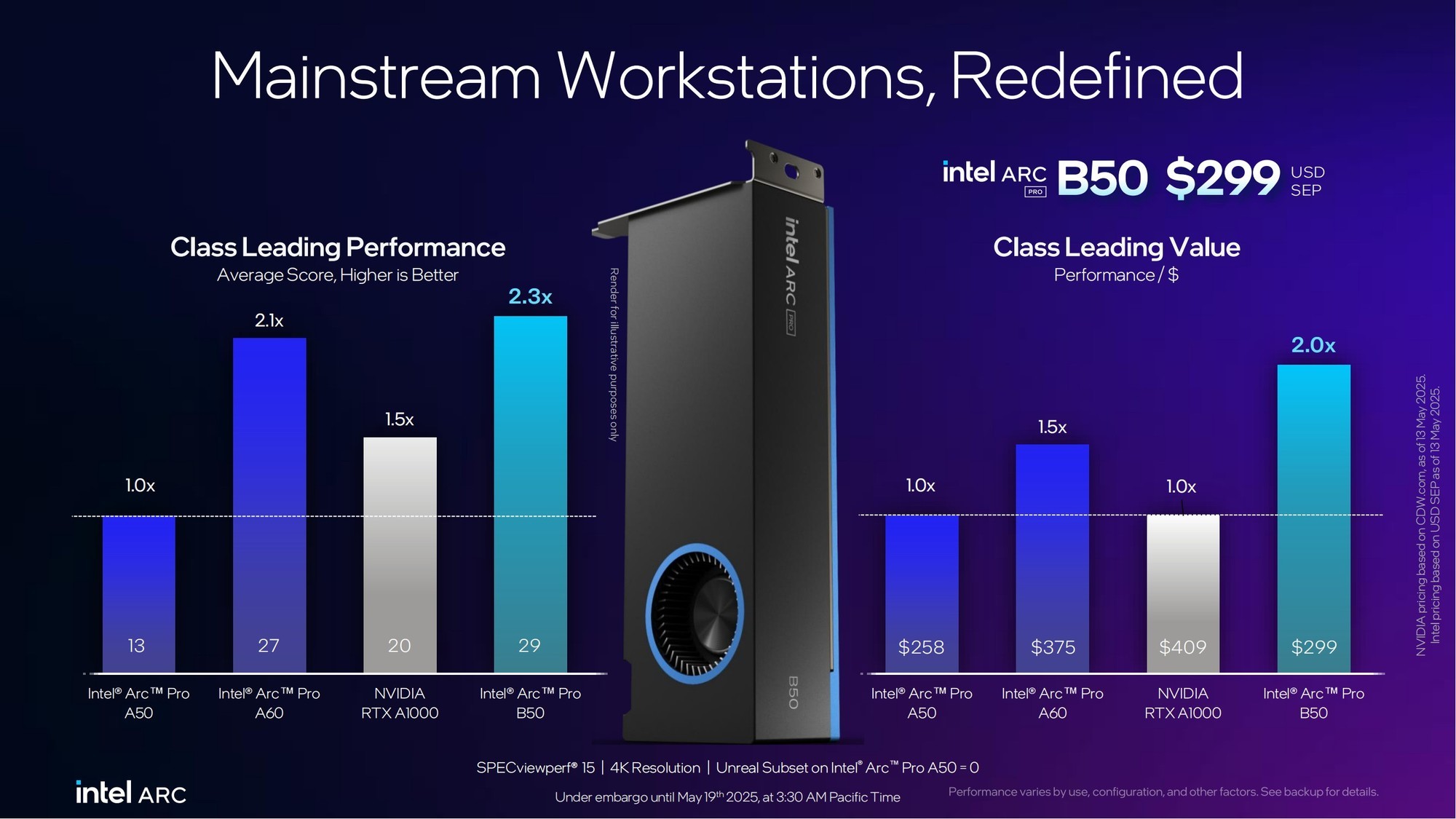
锐炫Pro B50作为面向图形工作站的产品,更大的显存为其带来了更加出色的性能表现。相对于自家上一代锐炫Pro A50/A60以及NVIDIA RTX A1000来说,锐炫Pro B50在各类工作站测试、生产力性能测试以及AI测试中提升显著。
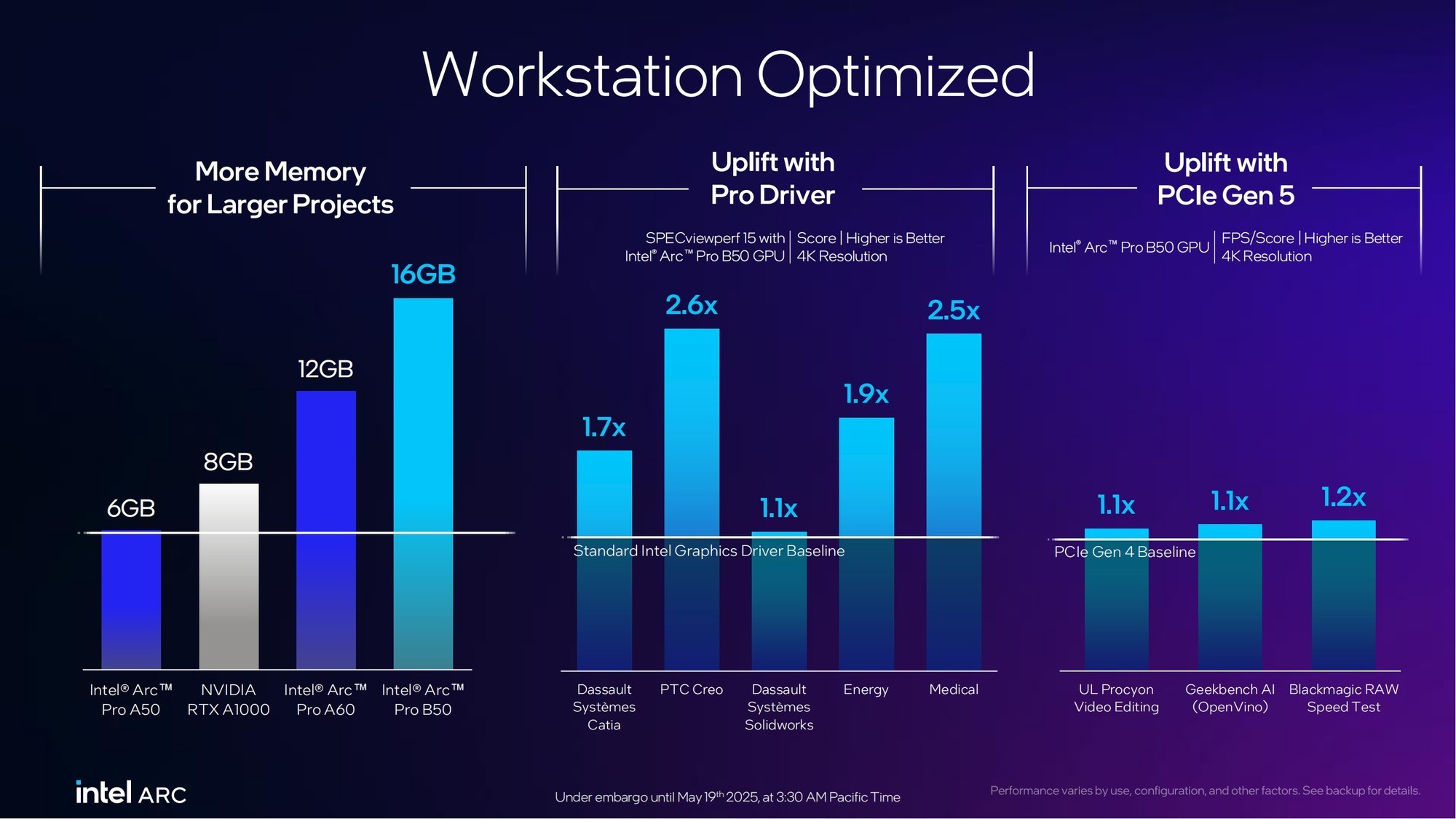
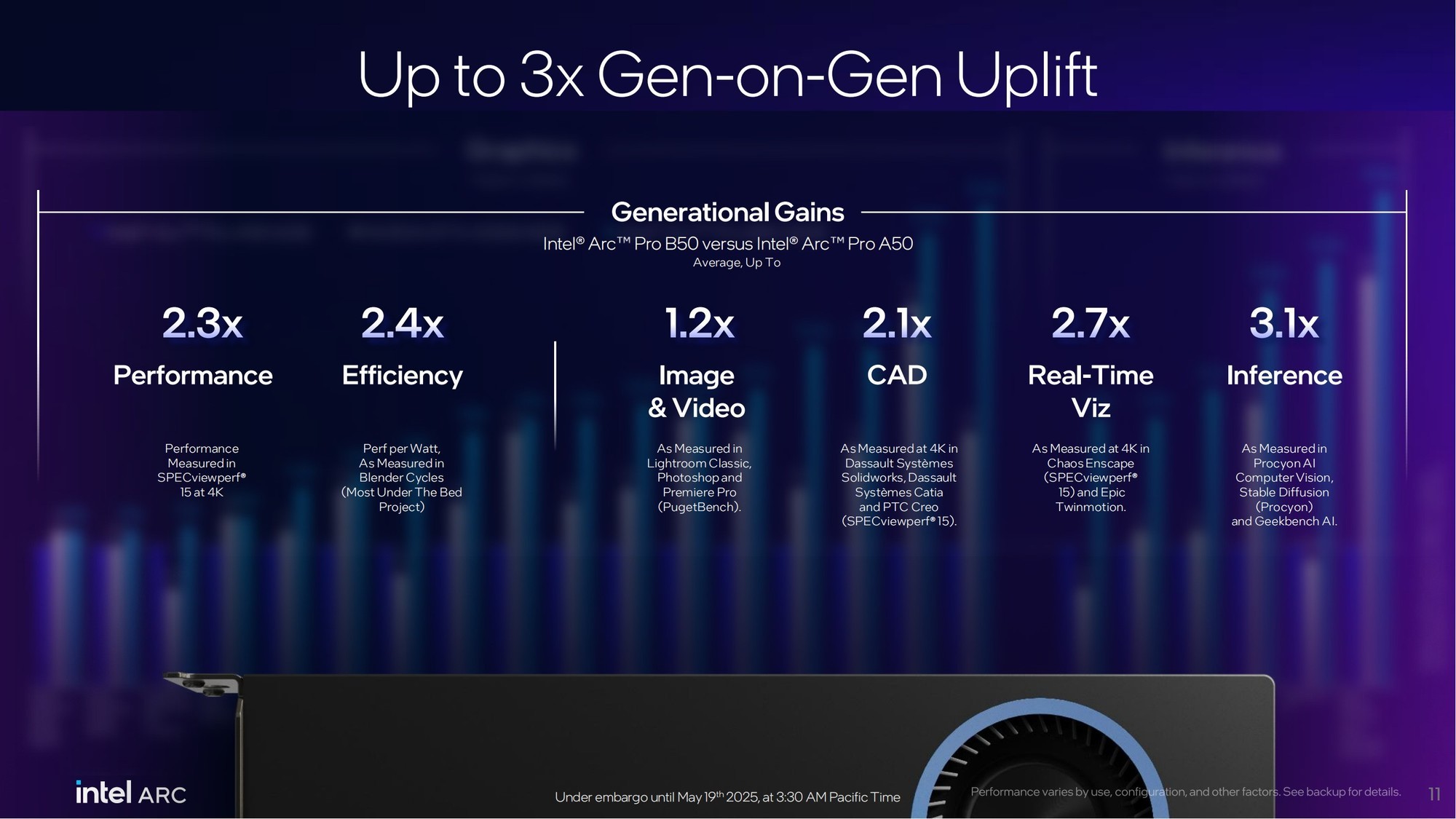
在更加细致的生产力相关图形性能方面以及推理性能方面,相比前代锐炫Pro A50以及NVIDIA RTX A1000来说,锐炫Pro B50代际提升幅度最高分别达到3.4倍和3.5倍。
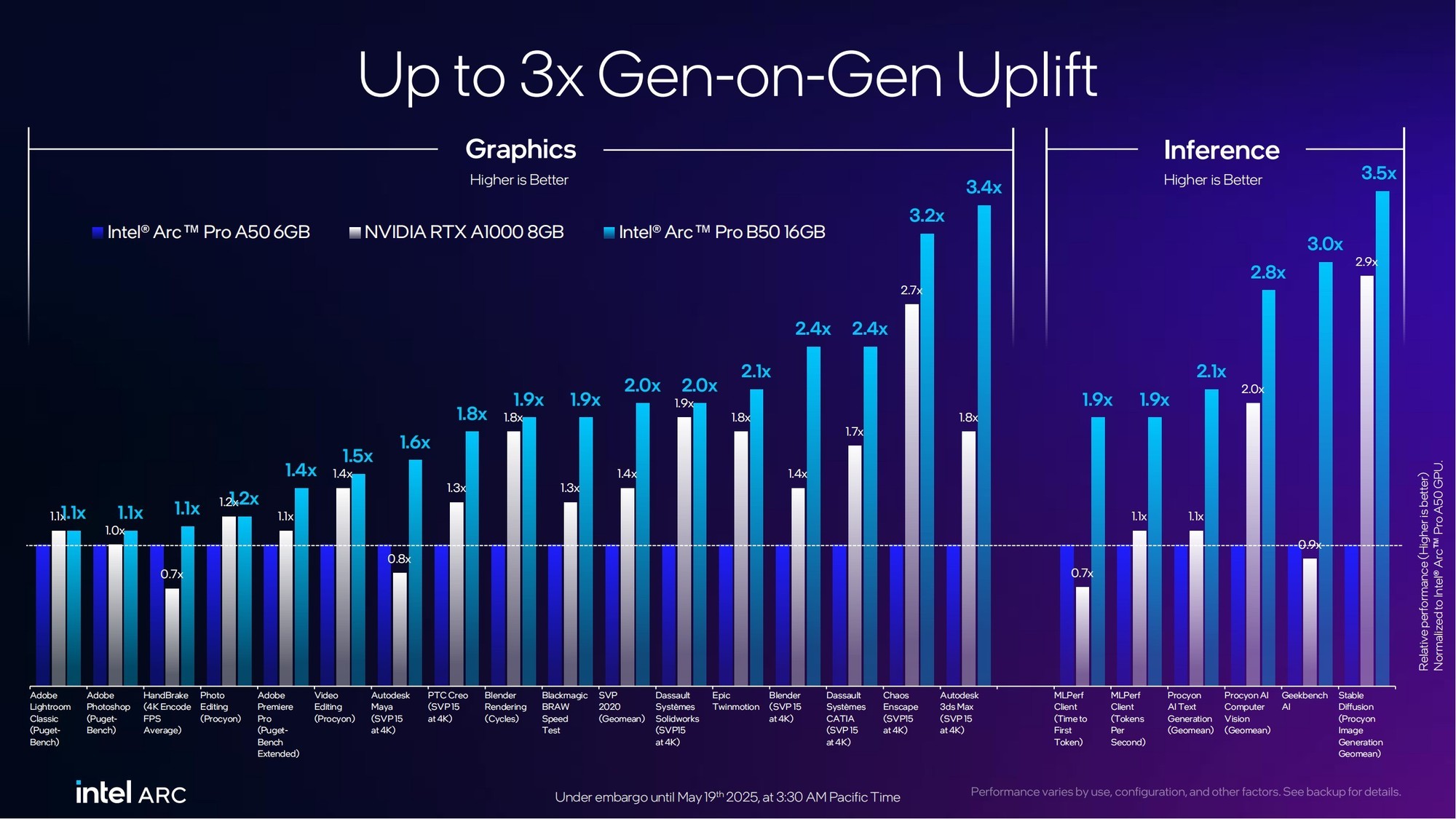
总体来看,锐炫Pro B50相对锐炫Pro A50而言,性能提升2.3倍、能效提升2.4倍,图片和视频编辑性能提升1.2倍,CAD性能提升2.1倍,实时3D渲染性能提升2.7倍,推理性能提升3.1倍!
锐炫Pro B50系列官方参考售价为299美元,依旧有着非常不错的性价比。
锐炫Pro B60主要面向AI推理工作站,这也是一块全新的市场拓展。
参数方面,锐炫Pro B60拥有20个Xe-Cores,支持24GB显存,456GB/s显存带宽,集成160个XMX矩阵引擎,INT8算力高达197TOPS,功耗区间为120-200W,同样支持PCIe5.0。
锐炫Pro B60支持Linux系统的多GPU扩展,支持虚拟化技术,有着出色的可管理性。

既然是面向AI推理的GPU,下面来看看锐炫Pro B60在各类大语言模型下的表现。
得益于24GB大显存设计,锐炫Pro B60在DeepSeek R1、Phi-4、QwQ、Qwen2.5以及Llama 3的各种参数规模以及不同数据类型的大语言模型的生成速度上,都要明显优于竞品,最高达到2.7倍领先。无愧于专业的AI推理计算卡定位。
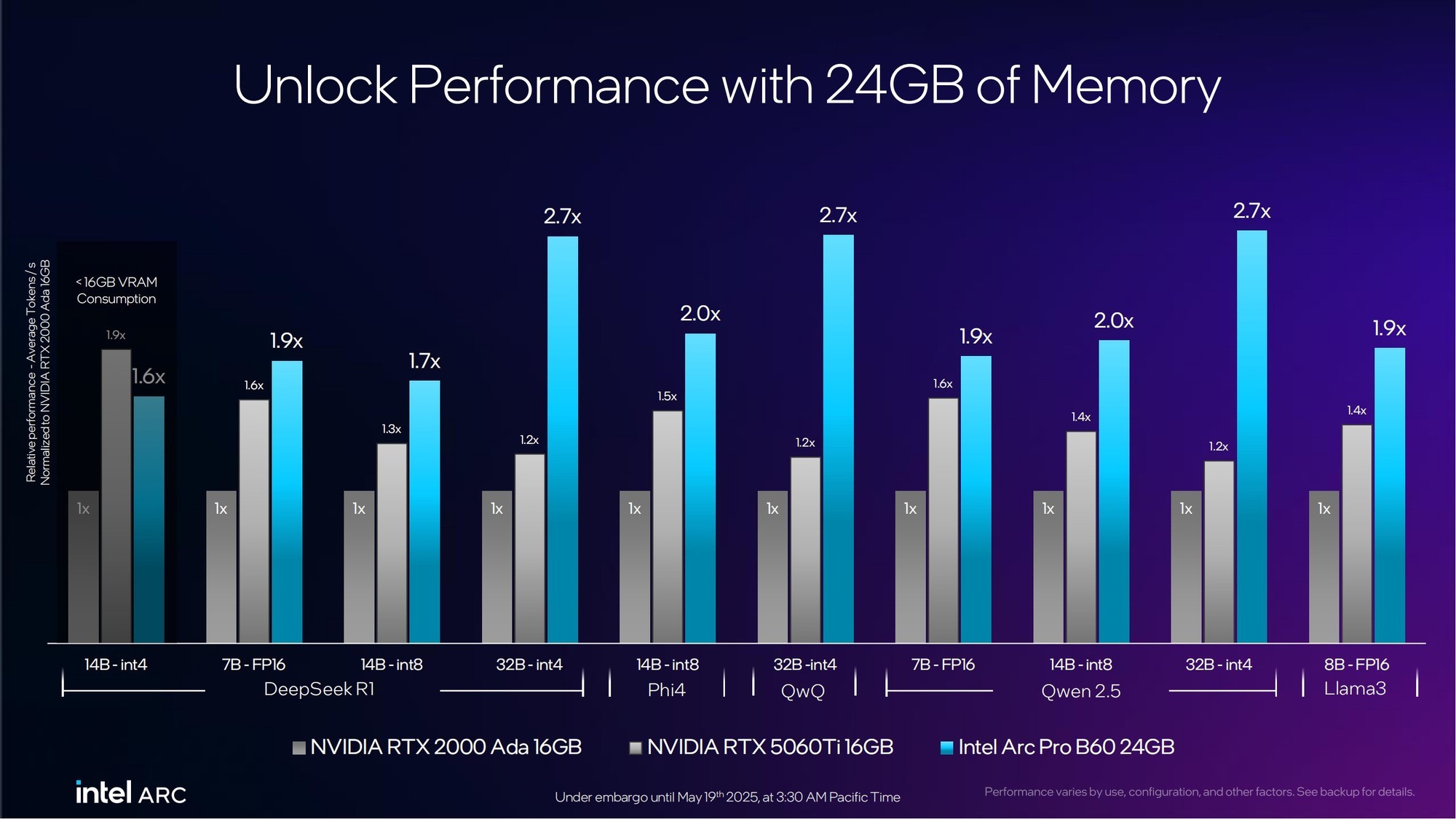
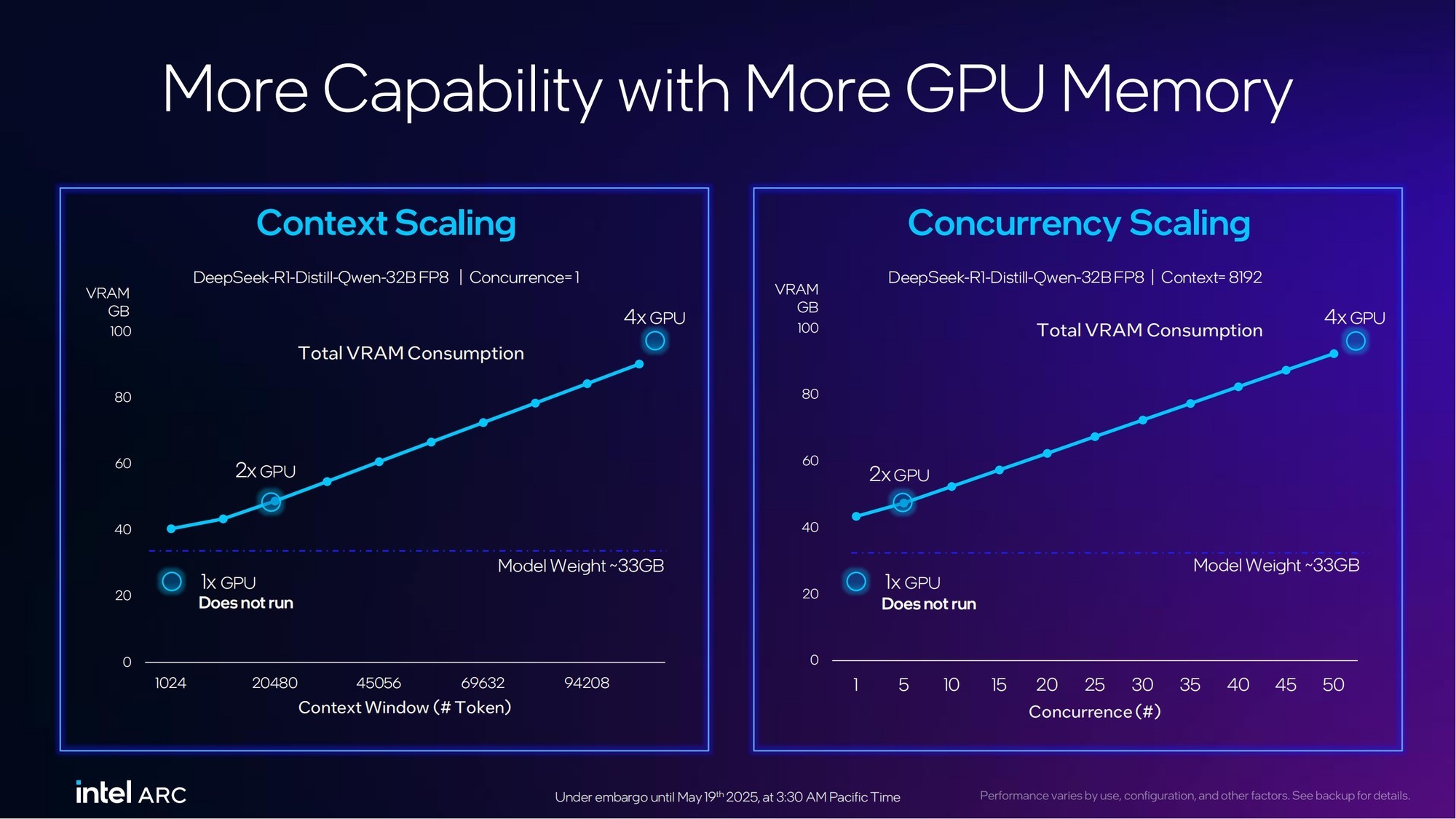
了解AI推理的朋友都知道,显存对于大语言模型生成速度的重要性不言而喻。不同参数规模以及不同数据类型的大语言模型对于显存的依赖虽然不同,但万变不离其宗的核心规律就是:显存越大速度越快。24GB显存的锐炫Pro B60无疑能够给有AI推理需求的企业用户带来更加高效的体验。同时,多卡协同还能实现70B超大规模参数大语言模型的运行。
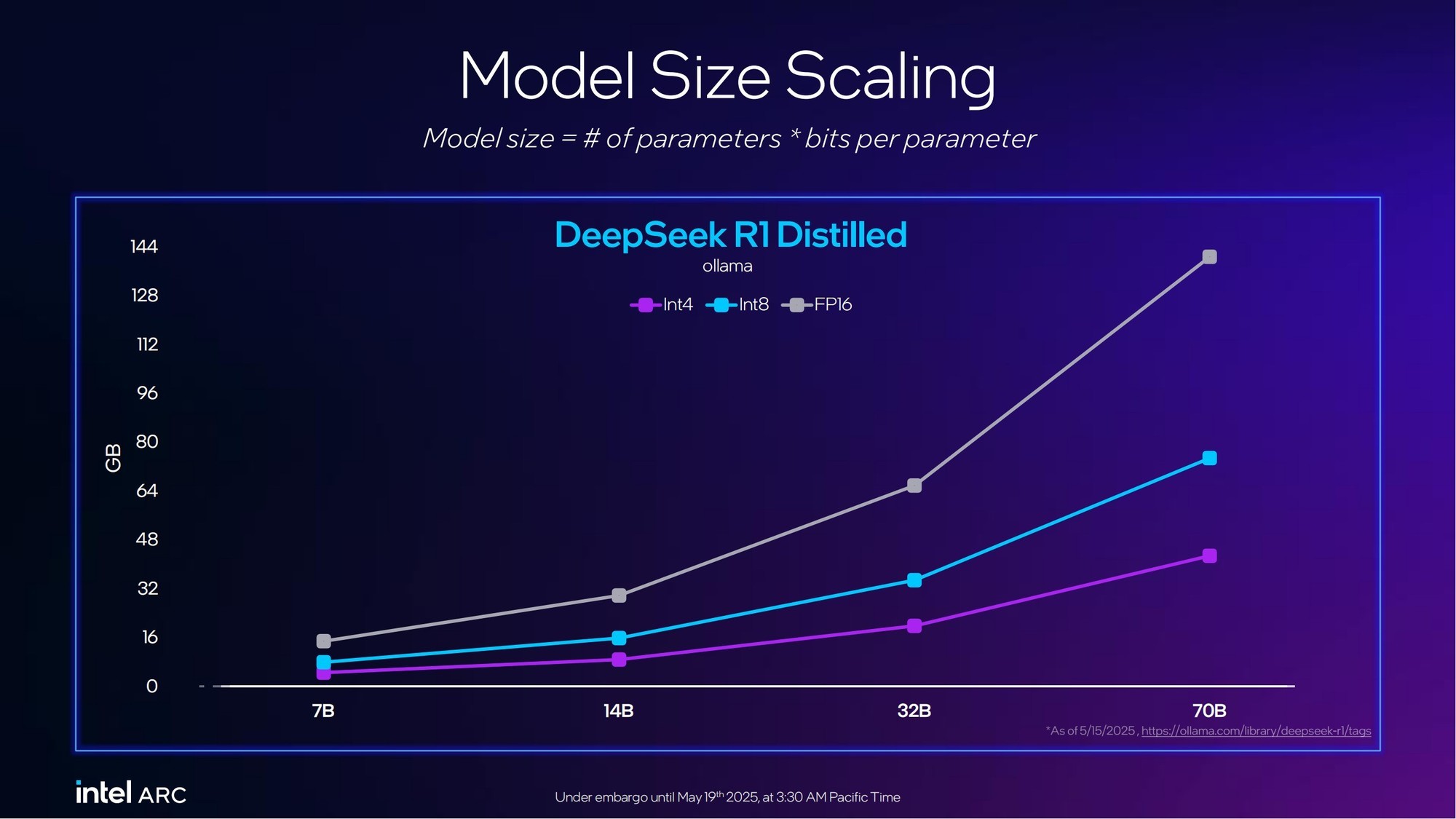
下面这张图,英特尔给出了单卡到4卡的显存变化所对应的内容窗口长度(tokens生成量),从中可以看到4卡集群在DeepSeek R1 32B FP8通义千问蒸馏大模型应用中的重要性。而这种特性在其它大模型中自然也适用。
对于多卡方案,英特尔提出了Project Battlematrix计划的推理工作站平台:基于英特尔至强平台,最高支持8张英特尔锐炫Pro GPU,总显存容量可达192GB,实现对70B以上参数规模的大语言模型的支持。

除了硬件之外,英特尔也构筑了Project Battlematrix Linux软件栈,系统化地提供了从驱动、库/工具到框架再到大语言模型服务的全栈式解决方案,为企业用户带来更加便捷的部署与使用体验。

据悉,锐炫Pro B50系列将会在零售渠道展开销售,锐炫Pro B60系列暂时只面向行业用户或企业用户按需定制。合作伙伴方面,已经有包括华擎、蓝戟、铭瑄等在内的数家厂商推出了前瞻设计。


英特尔锐炫Pro B50和B60系列将在今年三季度正式上市。