RX Vega最新性能曝光
AMD日前宣布,本月30日的SIGGRAPH大会上,将正式推出新一代消费级RX Vega显卡,其性能一直是玩家的关注焦点,但通过之前的Vega专业卡模拟跑分来看,其只能说勉强赶上GTX 1080。

今天,RX Vega游戏卡的性能跑分现身3D Mark 11,这是识别号687F:C1显卡的最新成绩,而且主频提高到了1630Mhz(显存频率从700MHz提高到945MHz),也就是比同样基于Vega 10核心的专业卡Vega FE还要高30MHz。其他规格方面,显存8GB HBM2,带宽484GB/s,结合Vega 10的核心面积,也就是每平方毫米提供1GB/s的速度。
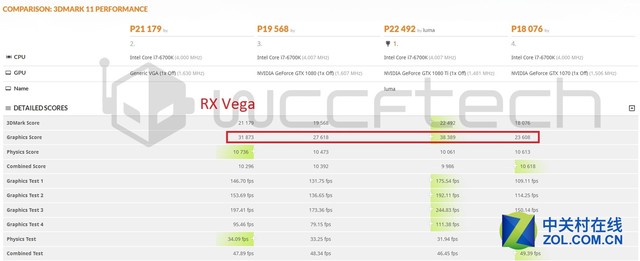
P模式下,RX Vega拿下31873分,对比之下,比GTX 1080快了15%,比GTX 1080 Ti慢了16%,比GTX 1070快了35%。

除了后发优势,另外就是用户综合成本的下降。RX Vega要做的就是提供2K/4K级别的超高体验,这不仅是对显卡本身的要求,还需要处理器、显示器等的 配合,比如FreeSync。对于NV的G-Sync,开源免授权费的Freesync有着非常明显的成本优势,转化到消费者一侧,就是体验不损失的情况下,节省一大笔钱。

关于RX Vega最后的产品布局还是十分神秘,但预计会有风冷、水冷和双芯产品,也就是满足游戏高玩的一切期待。
NV展示GPU多芯集成技术
前不久,Intel公布了网格互连(Mesh Interconnect)总线,提升多核CPU的效率和性能表现,取代QPI和环形总线。

相似的,AMD在今年的EPYC霄龙处理器上也使用了Infinity Fabric互连架构。
之所以要升级互联(连)架构,其实就是向摩尔定律的再挑战。如果仅仅是用“胶水”的方式拼接核心,带来的是大量的带宽和效率损失,而且芯片也会越来越大,甚至超越制程工艺本身进步。

据外媒报道,NVIDIA研究人员近日展示了自家的MCM(多芯片封装)技术,用于将CPU/GPU/存储器/控制器等整合,最直观的作用就是提高流处理器数、减少通讯层级和链路长度、缩小芯片面积。

我们知道,今年基于Volta架构的Tesla V100是NV史上最大的核心,面积达到815平方毫米,而且流处理器数只有5376(84组SM)。换言之,尽管换用了更先进的工艺,但Volta芯片面积比上一代的GP100核心(610平方毫米)还大。
新的MCM技术允许多个GPU模块与显存、控制器等在更小的面积内封装,按照NV的纸面模拟,一组256SM的新技术显卡可以做到16384个流处理器,比用传统手段搭建的28组SM多芯显卡性能提升45.5%,比同样流处理器数的多卡提升26.8%。

按照NV的设计思路,每个GPM(GPU模块)比目前的大核心都要小40%~60%之多,如果配合10nm/7nm工艺,可以在更小的体积中发挥更大的性能。
本文属于原创文章,如若转载,请注明来源:DIY周报:AMD Ryzen 3跑分曝光战平i5!//diy.zol.com.cn/646/6462857.html